Research Note: Veeam Acquires Object First, Consolidating Its Backup Appliance Strategy

Veeam recently confirmed its acquisition earlier this month of Object First, an immutable backup storage appliance vendor founded by Veeam’s original co-founders Ratmir Timashev and Andrei Baronov in 2022.
The transaction resolves a strategic conflict where Veeam competed directly with Object First’s Ootbi appliance while simultaneously offering its own Veeam Software Appliance for backup storage. The acquisition provides Veeam with purpose-built hardware capabilities to complement its software-first strategy.
Research Note: HPE’s New Networking & Compute (NRF 2026)

At the recent NRF 2026 in New York, HPE expanded its retail-focused infrastructure portfolio with new networking and compute capabilities intended for always-on retail environments. The announcements emphasize tighter integration between edge networking, cloud-native AI operations, and fault-tolerant compute to support transaction continuity, operational visibility, and distributed retail services.
Research Note: CrowdStrike’s Shopping Spree, Acquires SGNL and Seraphic

CrowdStrike announced two strategic acquisitions in January 2026 that extend its Falcon platform into browser runtime security and continuous identity authorization. The company acquired SGNL for $740 million and Seraphic Security for an undisclosed amount, with both transactions expected to close in Q1 FY2027.
Research Note: Dell PowerStore OS v4.3 brings Capacity Expansion and Enterprise Resilience Enhancements

Dell Technologies has released PowerStore OS v4.3, introducing higher-capacity QLC flash drives, expanded replication capabilities, and file system operational improvements.
Research Note: Dynatrace Acquires DevCycle, Integrating Observability & Feature Management

Dynatrace this week announced the acquisition of DevCycle, a feature management platform built on the OpenFeature standard. The acquisition addresses a fundamental gap in modern software delivery: the disconnect between feature flag controls and runtime observability.
Research Note: Snowflake Acquires Observe, Advancing Data Platform & Observability Integration

Snowflake recently announced a definitive agreement to acquire Observe, an AI-powered observability platform built on Snowflake’s infrastructure. Valued at approximately $1 billion, this is Snowflake’s second observability-related acquisition, after TruEra in May 2024.
These acquisitions challenge the traditional separation between observability infrastructure and data platforms. By treating telemetry data (logs, metrics, traces) as first-class data within Snowflake rather than requiring specialized observability infrastructure, the combined offering promises to reduce observability costs while enabling full-fidelity data retention.
“Chips” is now the “C” in CES

While the focus of CES 2026 remained on consumer electronics, this year felt different. More expansive, with the semiconductor industry dominating the pre-show with overlapping announcements that reveal diverging strategies for AI workload acceleration, manufacturing sovereignty, and market expansion beyond traditional computing segments.
Research Report: Cisco FlashStack with Nutanix
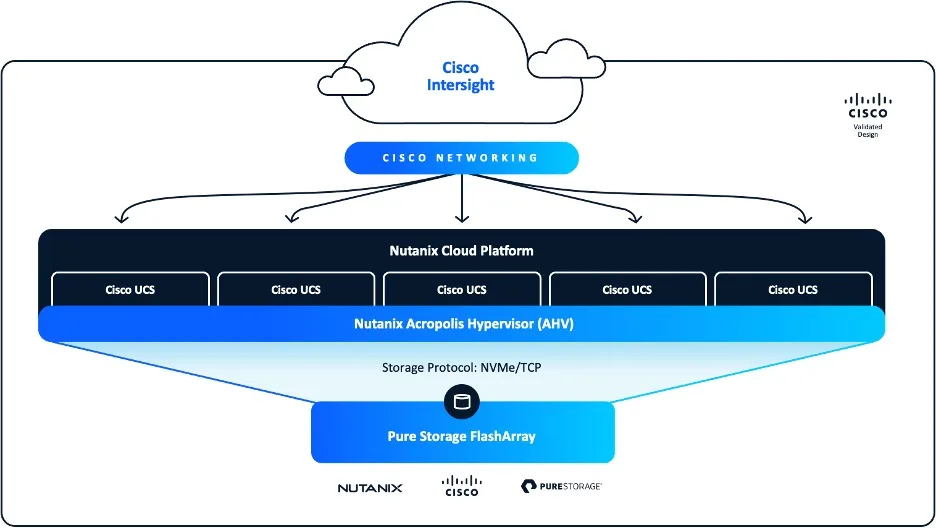
The enterprise infrastructure market is faced with disruption across multiple fronts. Traditional virtualization platforms face unprecedented disruption, while emerging AI-first workloads demand architectures that seamlessly span on-prem, cloud, and edge environments.
It’s against this backdrop that Nutanix, Cisco, and Pure Storage have collaborated to reimagine converged infrastructure with Cisco’s FlashStack with Nutanix.
Research Note: Qualcomm Validates Wi‑Fi 8 Silicon with LitePoint — A Key Readiness Milestone

For enterprise leaders the marketing noise of Wi-Fi 8 is beginning to be replaced by concrete readiness indicators.
Building the “Always‑On” Store – HPE’s Practical Approach to Retail at NRF 2026

HPE’s presence at NRF 2026 shows a broader industry shift toward “always‑on” retail
Stop Buying Labels and Start Buying Silicon

Most buyers never ask about it.
Most vendors never volunteer it.
But it’s the only part of the AP that actually matters: the silicon.
Research Note: VAST’s Novel Approach to NVIDIA’s new CMX Inference Context Memory Storage Platform

VAST Data announced support for NVIDIA’s recently unveiled Inference Context Memory Storage (ICMS) Platform, targeting the NVIDIA Rubin GPU architecture. The announcement addresses the challenge of managing KV cache data that exceeds GPU and CPU memory capacity as context windows scale to millions of tokens across multi-turn, agentic AI workflows.
Research Note: Improving Inference with NVIDIA’s ‘CMX’ Inference Context Memory Storage Platform

At NVIDIA Live at CES 2026, NVIDIA introduced its Inference Context Memory Storage (ICMS) platform as part of its Rubin AI infrastructure architecture. NVIDIA’s ICMS addresses KV cache scaling challenges in LLM inference workloads.
The technology targets a specific gap in existing memory hierarchies where GPU high-bandwidth memory proves too limited for growing context requirements while general-purpose network storage introduces latency and power consumption penalties that degrade inference efficiency.
NVIDIA at CES: When the Compute Stack Outgrew the Showroom
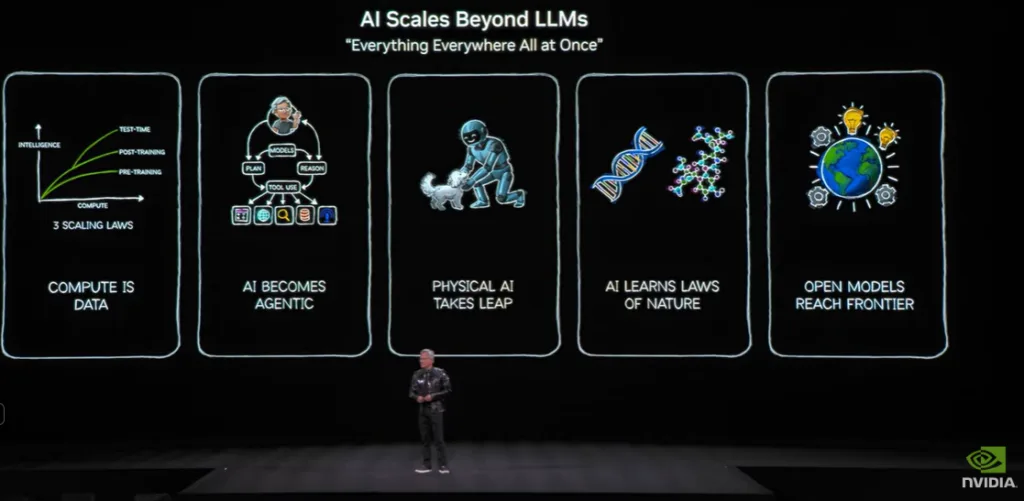
Jensen used the stage to argue that the world is shifting from CPU‑centric computing to AI‑driven, GPU‑first platforms, and the shift isn’t just for hyperscalers.
Research Note: Dynatrace & Google Cloud Collaborate on Observability for Agentic AI
Dynatrace and Google Cloud have expanded their collaboration to provide observability capabilities for agentic AI workloads through two primary integrations: a Gemini CLI extension for developer access to observability data within terminal environments, and an A2A protocol integration with Gemini Enterprise for real-time system monitoring.