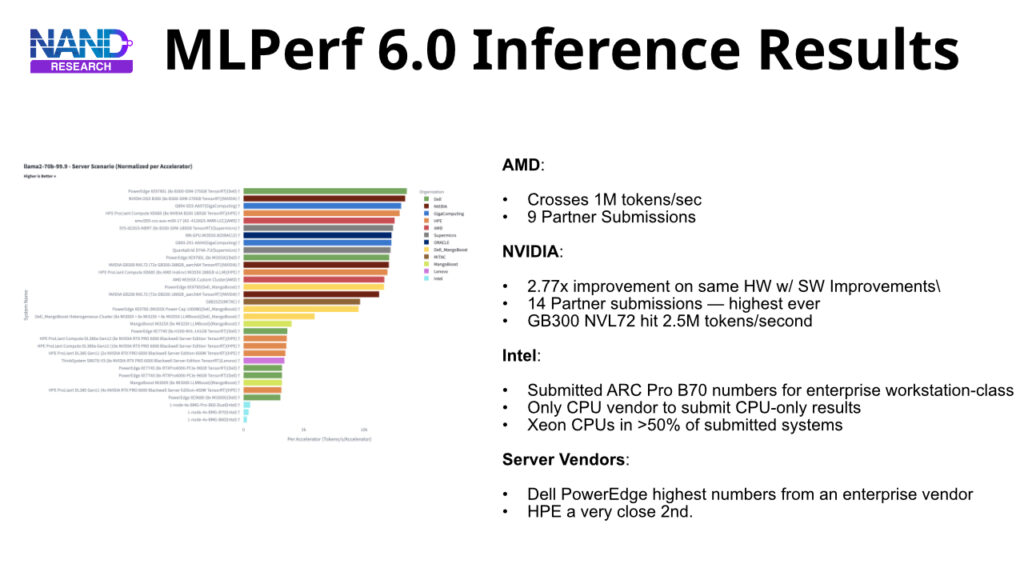
MLCommons released MLPerf Inference v6.0 results, marking what the consortium describes as the most significant update to the benchmark suite to date.
The round introduced five new workloads, including a multimodal vision-language model, a text-to-video generation benchmark, and a new interactive scenario for the DeepSeek-R1 reasoning model.
NVIDIA swept the new benchmarks on Blackwell Ultra hardware, but the more consequential storyline is the role software optimization played in driving performance gains on existing hardware;
- AMD extended its ecosystem reach with the Instinct MI355X
- Intel introduced Arc Pro B-Series GPUs for accessible inference
- NVIDIA’s partner ecosystem grew to its largest recorded count.
Together, the results offer enterprise buyers a sharper picture of where inference performance is heading and what it costs.
New Workloads Shift Toward Frontier Models and Multimodal AI
MLPerf Inference v6.0 introduced five new tests that better align the benchmark suite with current production workloads operators manage today.
The suite now includes areas such as text-to-video generation, multimodal vision-language reasoning, and high-interactivity LLM serving, which previous versions only partially addressed or not at all.
| Benchmark | Description | Scenarios |
| DeepSeek-R1 Interactive | New Interactive scenario added to the existing DeepSeek-R1 test, requiring 5x the minimum token rate and 1.3x shorter time to first token compared to the Server scenario. | Interactive (new) |
| Qwen3-VL-235B-A22B | A vision-language model with 235 billion total parameters, the first multimodal model in the MLPerf Inference suite. | Offline, Server |
| GPT-OSS-120B | A 120-billion-parameter mixture-of-experts reasoning LLM from OpenAI. Provides a fresh benchmark data point on MoE model inference performance across platforms. | Offline, Server, Interactive |
| WAN-2.2-T2V-A14B | A 14-billion-parameter text-to-video generative model. The first video generation workload in MLPerf Inference | Single-Stream, Offline |
| DLRMv3 | A transformer-based generative recommendation model replacing the prior DLRM-DCNv2 benchmark. Raises compute intensity and model size to better reflect hyperscale and large-retailer workloads. | Offline, Server |
Only the NVIDIA platform submitted results across all five new benchmarks and scenarios.
Software Optimization Drives Larger Performance Gains
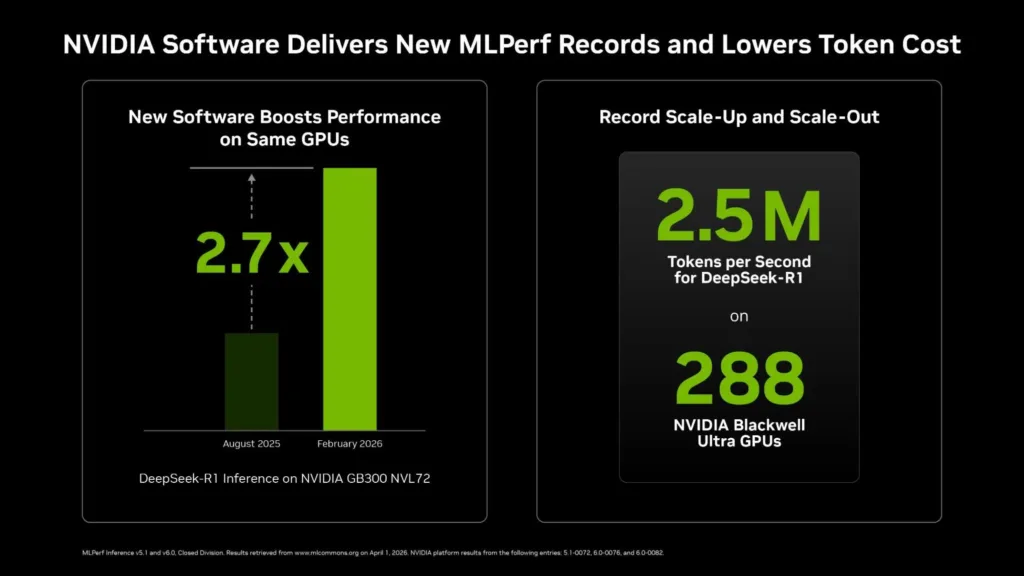
The key finding in v6.0 is the significant performance boost achieved by software running on existing hardware.
NVIDIA’s TensorRT-LLM and Dynamo frameworks achieved measurable throughput improvements on GB300 NVL72 systems, first deployed six months ago, with partner submissions independently confirming the results.
The implication for buyers is that the value of a GPU platform is not fixed at deployment but can be enhanced through tuning and optimization of the underlying software stack.
| Submitter | Platform | Key Result |
| NVIDIA / Nebius | GB300 NVL72 (72x Blackwell Ultra GPUs) | – 2.77x per-GPU throughput gain on DeepSeek-R1 Server vs. the same hardware six months prior (v5.1 debut). – Full-rack configuration reached 2.5 million tokens/sec, a system-level record. – Gains driven by kernel fusion, optimized attention data parallelism, disaggregated serving (Dynamo), Wide Expert Parallel, Multi-Token Prediction, and KV-aware routing. |
| Lambda Labs (Closed) | GB300 Blackwell Ultra (4-GPU tray) vs. HGX B200 | -29% higher throughput on GPT-OSS-120B using Blackwell Ultra vs. Blackwell on identical software, a pure hardware generational lift. – Separate closed-division result: upgrading the CUDA stack on the same HGX B200 hardware from v5.1 delivered a 9% throughput gain on Llama 3.1 8B. |
| Lambda Labs (Open) | HGX B200 (8-GPU) | BLAZE, a runtime MoE routing optimization developed with Stevens Institute of Technology, reduced time-to-first-token P99 latency by 31% on GPT-OSS-120B with no model retraining required. |
| Lenovo | ThinkSystem SR680a V4 (HGX B300) and SR675i V3 (RTX PRO 6000) | – Covered both large-scale data center inference and GPU-dense inference configurations optimized for enterprise deployment. – SR680a V4 targets AI factory-scale workloads with liquid cooling. SR675i V3 is positioned for inference-optimized enterprise servers. |
The common theme across NVIDIA ecosystem submissions is that ongoing software investment prolongs the lifespan of installed hardware.
For enterprises that have implemented Blackwell-generation systems, the performance ceiling shown in v6.0 is significantly higher than what those systems reached at launch.
AMD Extends Ecosystem Breadth; Intel Targets Accessible Inference
The v6.0 round yielded significant results from vendors outside the NVIDIA ecosystem. AMD and Intel both improved their inference platforms in ways that matter to buyers assessing alternatives for specific price-performance and deployment needs.
| Platform | v6.0 Highlights |
| AMD Instinct MI355X | – CDNA 4 architecture with 288 GB HBM3E and native FP4/FP6 support. – Exceeded 1 million tokens/sec on multi-node cluster deployments of Llama 2 70B and GPT-OSS-120B. – Nine partners (Cisco, Dell, HPE, Oracle, Supermicro, Red Hat, and others) submitted results across four Instinct GPU generations (MI300X through MI355X), with partner results landing within 4% of AMD’s own submission. – First-time results on GPT-OSS-120B and WAN-2.2-T2V. Roadmap advances to MI400 Series on CDNA 5 and Helios rack-scale architecture in 2026. |
| Intel Arc Pro B70 + Xeon 6 | – Targets workstation, edge, and accessible data center inference. A 4-GPU configuration delivers 128 GB of total VRAM, sufficient to run 120B-parameter models without model splitting. – Arc Pro B70 delivered up to 1.8x the inference performance of the Arc Pro B60. – Intel remains the only server processor vendor to submit a standalone CPU-only MLPerf Inference result – Xeon CPUs were present in more than half of all v6.0 submissions from other vendors. |
AMD’s nine-partner ecosystem submitting in v6.0 ties its record for most partners submitting on the platform in a single round, showing a growing commercial maturity beyond the flagship MI355X itself.

Intel’s contribution is narrower in scope but targets a segment of the market, professional workstations and edge inference servers, that the headline GPU clusters do not serve.
NVIDIA Platform Dominance, Partner Ecosystem Breadth, and What It Means for Buyers
NVIDIA’s cumulative MLPerf training and inference wins since 2018 have reached 291 with v6.0, a number NVIDIA reports as nine times that of all other submitters combined. Fourteen partner organizations submitted on NVIDIA hardware in this round, the highest count for any platform in a single MLPerf cycle.
The breadth matters because partner results demonstrate that benchmark performance is reproducible outside NVIDIA’s own lab environment.
For enterprise buyers, v6.0 enhances several decision-critical data points:
- NVIDIA: software-driven improvements on existing hardware are significant and impactful, with increases of up to 2.77 times throughput on a six-month-old system. This shifts the economics of capital planning, as infrastructure doesn’t depreciate as quickly as the hardware refresh cycle might suggest.
- AMD: the MI355X is now a validated alternative for multi-node LLM inference deployments, with an ecosystem that has expanded to support production procurement decisions.
- Intel: The Arc Pro B-Series entry targets the inference accelerator market below the hyperscale cluster segment, providing a TCO framework for professional and enterprise edge buyers.
Final Thoughts
MLPerf Inference v6.0 establishes inference benchmarking as a comprehensive discipline, where software frameworks, serving architectures, and interconnect topology all significantly impact results, just as much as raw silicon.
As NVIDIA approaches the Vera Rubin platform and AMD promotes the MI400 Series and Helios rack-scale architecture into production, the focus for the next round will shift from peak throughput to sustained efficiency at scale, across a model landscape that continues to diversify faster than any single benchmark cycle can fully capture.