At NVIDIA Live at CES 2026, NVIDIA introduced its Inference Context Memory Storage (CMX) platform as part of its Rubin AI infrastructure architecture. NVIDIA’s CMX addresses KV cache scaling challenges in LLM inference workloads.
The technology targets a specific gap in existing memory hierarchies where GPU high-bandwidth memory proves too limited for growing context requirements while general-purpose network storage introduces latency and power consumption penalties that degrade inference efficiency.
CMX establishes what NVIDIA terms a “G3.5” storage tier between local node storage and shared network storage, using BlueField-4 data processing units to manage flash-based context memory at the pod level.
NVIDIA claims the platform delivers 5x higher tokens-per-second and 5x better power efficiency compared to traditional storage approaches for long-context inference workloads.
The Challenge
Modern AI inference workloads have evolved beyond simple prompt-response patterns. Production deployments now involve long-lived interactions with extensive context requirements like multi-turn conversations, agentic workflows with tool use, and reasoning chains that maintain state across sessions and services.
The fundamental problem emerges when context windows grow beyond hundreds of thousands or millions of tokens. At these scales, KV cache data quickly exceeds the memory capacity of individual GPU and CPU resources.
Traditional storage architectures introduce multiple bottlenecks when serving this data. The data path typically involves numerous copy operations: SSD to storage controller, controller to file server, file server to host CPU memory, and finally CPU memory to GPU memory. Each copy operation adds latency, directly impacting TTFT metrics that determine inference responsiveness.
Concurrency presents an additional challenge. Standard client-server storage models assume statistical workload distribution where not all clients access storage simultaneously. KV cache workloads violate this assumption. In inference clusters, GPU hosts continuously read and write context data concurrently, creating resource contention at storage servers that quickly becomes the limiting factor for cluster-wide throughput.
Technical Details
NVIDIA CMX lives within a four-tier memory and storage hierarchy governing KV cache placement in transformer-based inference systems. The hierarchy is built around the fundamental tradeoffs between access latency, capacity, and power efficiency that become critical as context windows extend into millions of tokens and models scale toward trillions of parameters.
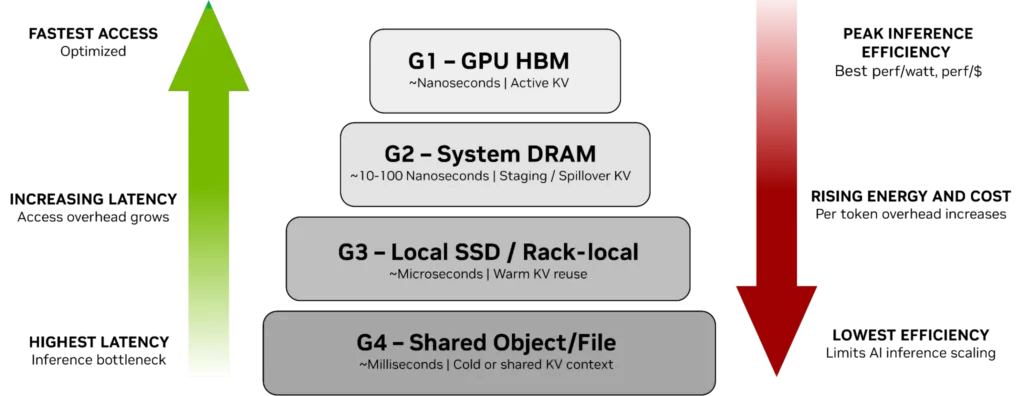
The tiers consist of:
- G1 (GPU HBM): Provides nanosecond-scale access for active KV cache directly involved in token generation; the highest performance tier, but with capacity limited to what fits in GPU on-package memory
- G2 (System DRAM): Serves as staging and overflow capacity for KV cache evicted from HBM, with access latency in the 10-100 nanosecond range, but capacity constrained to single-node memory configurations
- G3 (Local SSDs): Extends warm KV cache storage to microsecond-scale access for context reused across shorter timescales, but remains node-local and does not support cross-node sharing without additional data movement
- G4 (Shared Storage): Provides practically unlimited capacity and cross-node access, but introduces millisecond-scale latency and was architected for durable enterprise data rather than ephemeral, re-computable inference context
CMX introduces an intermediate “G3.5” tier that NVIDIA describes as “pod-level context memory” designed specifically for KV cache data characteristics.
This tier provides Ethernet-attached flash storage managed by BlueField-4 processors that operate as both storage controllers in dedicated CMX enclosures and as DPU accelerators in Rubin compute nodes.
The architecture bridges the capacity limitations of G1-G3 tiers with the cross-node sharing capabilities of G4 while avoiding the latency and power consumption penalties associated with general-purpose storage infrastructure.
BlueField-4 Implementation
BlueField-4 is as the fundamental building block for CMX, functioning as both the storage controller in dedicated flash enclosures and as a data movement accelerator in Rubin compute nodes.
The processor integrates 800 Gb/s network connectivity, a 64-core NVIDIA Grace CPU complex, and LPDDR memory with dedicated hardware acceleration for cryptographic operations and CRC-based data integrity checking.
In its launch, NVIDIA emphasized several architectural elements that differentiate BlueField-4 from traditional storage controllers:
- BlueFied-4 performs line-rate encryption and data integrity operations at full 800 Gb/s bandwidth without consuming Grace CPU cycles (enabling inline protection for KV cache flows without introducing latency penalties).
- NVMe and NVMe-oF transport support including NVMe key-value extensions that align with the block-oriented nature of KV cache management in inference frameworks.
- RDMA offload capabilities reduce host CPU involvement in KV cache transfers between compute nodes and CMX targets (preserving host CPU resources for inference serving).
- Integration with NVIDIA’s DOCA framework provides KV-specific communication and storage abstractions for managing context cache as a distinct data class
NVIDIA describes BlueField-4 as enabling a “stateless and scalable approach” to KV cache management, though this characterization requires qualification.
While individual KV blocks may be treated as stateless and re-computable, the overall inference context maintained across multi-turn agentic workflows represents stateful session information that orchestration layers must track and coordinate.
BlueField-4 offloads the data movement and storage protocol termination, but frameworks like NVIDIA Dynamo and NIXL still maintain state about KV block locations, validity, and sharing across inference instances.
Power Efficiency and Performance Claims
NVIDIA claims CMX delivers 5x improvements in both tokens-per-second and power efficiency compared to traditional storage approaches for long-context inference. These claims require careful examination of the comparison baseline and workload characteristics that determine whether these benefits materialize in production deployments.
The power efficiency advantage derives from several architectural decisions that differentiate CMX from general-purpose storage:
CMX treats KV cache as ephemeral, re-computable data that does not require the durability, replication, and consistency mechanisms that general-purpose storage systems provide for long-lived enterprise datasets.
By eliminating background processes like metadata management, replication, and integrity checking that consume power without contributing to inference throughput, CMX reduces the energy cost per token served.
However, this assumes that the cost of recomputing KV cache when CMX experiences failures or data loss remains lower than the energy cost of providing traditional durability guarantees, which may not hold for all workload patterns or failure scenarios.
BlueField-4’s hardware acceleration for encryption and data integrity operations reduces CPU power consumption compared to software-based approaches in traditional storage controllers. The vendor specifies line-rate performance at 800 Gb/s for these functions, suggesting minimal impact on data path latency or throughput. However, organizations must still account for the base power consumption of BlueField-4 processors themselves, which includes the 64-core Grace CPU complex and LPDDR memory in addition to acceleration engines.
The 5x tokens-per-second improvement depends critically on prestaging effectiveness and the ability to keep GPUs fed with necessary KV cache without introducing decode stalls. NVIDIA attributes this gain to “reliable prestaging” that minimizes idle GPU cycles and avoids redundant re-computation of inference context.
Competitive Environment
There is no directly comparable proprietary technology to NVIDIA’s CMX platform from AMD, Intel, or other vendors. However, there are several alternative approaches and open-source solutions that address similar KV cache management challenges across different hardware platforms.
Open-Source and Vendor-Neutral Solutions
LMCache is the primary vendor-neutral alternative for KV cache management. The open-source project, developed at the University of Chicago, provides hierarchical KV cache storage and sharing capabilities that work across multiple hardware platforms including NVIDIA GPUs, AMD MI300X accelerators, and Intel Gaudi 3 processors.
LMCache integrates with vLLM and SGLang inference engines to enable KV cache offloading to CPU memory, local storage, and network storage using standard protocols like S3. The system supports both cache offloading for prefix reuse across queries and prefill-decode disaggregation for cross-engine cache transfer.
Unlike NVIDIA’s CMX, which requires BlueField-4 DPUs and Spectrum-X Ethernet, LMCache operates over standard TCP/IP networking and works with commodity storage infrastructure. It’s an approach prioritizing ecosystem compatibility over specialized hardware acceleration that NVIDIA provides with BlueField-4.
AMD MI300X
AMD’s MI300X does not offer a dedicated KV cache storage platform equivalent to CMX. Instead, the architecture addresses KV cache challenges through substantially larger on-accelerator memory capacity.
The MI300X provides 192GB of HBM3 memory with 5.3 TB/s bandwidth, allowing entire large models (like LLaMA2-70B) to fit in memory while still accommodating KV cache, which avoids network overhead by preventing model splitting across GPUs.
AMD’s memory-centric approach differs fundamentally from NVIDIA’s strategy of creating an intermediate storage tier. AMD positions the large memory capacity as eliminating the need for aggressive KV cache offloading in many scenarios, though this comes at higher per-accelerator cost and does not address sharing KV cache across multiple inference instances.
AMD leverages vLLM’s PagedAttention for KV cache management within GPU memory, and MI300X deployments can utilize LMCache for offloading to external storage when needed.
AMD’s vLLM implementation uses KV cache management through paged attention to avoid memory fragmentation issues, enabled by the large memory capacity of MI300X accelerators.
Intel Gaudi 3
Intel’s Gaudi 3 similarly lacks a proprietary KV cache storage solution comparable to CMX. The platform instead emphasizes integrated networking capabilities for distributed inference.
Gaudi 3 features integrated networking with Ethernet fabric that allows direct communication between accelerators, potentially enabling distributed batch processing or model parallel inference across cards with less overhead.
Like AMD, Intel Gaudi deployments rely on standard inference frameworks like vLLM combined with LMCache for hierarchical KV cache management. The platform’s 128GB of memory per accelerator provides reasonable capacity for KV cache, though substantially less than AMD’s MI300X.
Analysis
NVIDIA’s CMX platform highlights broader trends in AI infrastructure evolution that extend beyond any single vendor’s solution. As inference workloads transition from experimental to production deployment at scale, infrastructure requirements are fundamentally changing:
- Convergence of storage and compute infrastructure continues to accelerate: running storage services on DPUs embedded in GPU servers is a step toward more integrated, purpose-built AI infrastructure platforms.
- Memory hierarchy for AI workloads is expanding beyond GPU and CPU memory: it now includes new persistent tiers with distinct performance and cost characteristics.
- Ecosystem requirements for production AI infrastructure are becoming more complex and interdependent: solutions increasingly require specific combinations of GPUs, DPUs, network fabrics, orchestration frameworks, and storage platforms.
Extending KV cache to solve the context window problem is not a new concept. Several storage vendors have already implemented architectural approaches for offloading or extending KV cache to NVMe-based storage infrastructure:
- Hammerspace offers this capability through its Tier Zero technology
- VAST Data provides an open-source implementation called VAST Undivided Attention (VUA)
- WEKA addresses the requirement with its Augmented Memory Grid platform.
- Dell has integrated LMCache and NIXL technologies with its PowerScale, ObjectScale, and Project Lightning (currently in private preview) storage systems to enable KV cache offload capabilities across these three storage engines.
NVIDIA, with this announcement, validates the approach with purpose-built infrastructure while also codifying an implementation that should make it easy for external storage providers to support – at least for NVIDIA systems. Customers in heterogeneous environments will need to think carefully about their choices.
NVIDIA’s approach is sound in principle: establish an intermediate storage tier between capacity-constrained local storage and latency-challenged network storage to improve both performance and power efficiency for long-context inference.
BlueField-4’s hardware acceleration and RDMA capabilities are foundational to the approach, while integration with Dynamo and NIXL enables orchestration frameworks to leverage CMX as part of a comprehensive KV cache management strategy.
NVIDIA highlighted during its launch that it has most of the storage industry supporting the effort, including AIC, Cloudian, DDN, Dell Technologies, HPE, Hitachi Vantara, IBM, Nutanix, Pure Storage, Supermicro, VAST Data and WEKA. NetApp and Lenovo have no yet announced support, but we expect that will happen before the technology is generally available in 2H 2026 (of the storage companies listed, NVIDIA CEO Jensen Huang called out NetApp specifically during his keynote).
Enterprises operating at sufficient scale to encounter KV cache capacity and efficiency constraints (such as neoclouds and large enterprise) should evaluate CMX as part of broader infrastructure planning for agentic AI deployments. The platform solves a real problem that will intensify as context windows and model parameters continue to grow.
As the industry continues scaling inference workloads, the separation between performance-optimized ephemeral data and durability-optimized persistent data is increasingly important. NVIDIA’s CMX provides a compelling approach for addressing this separation.