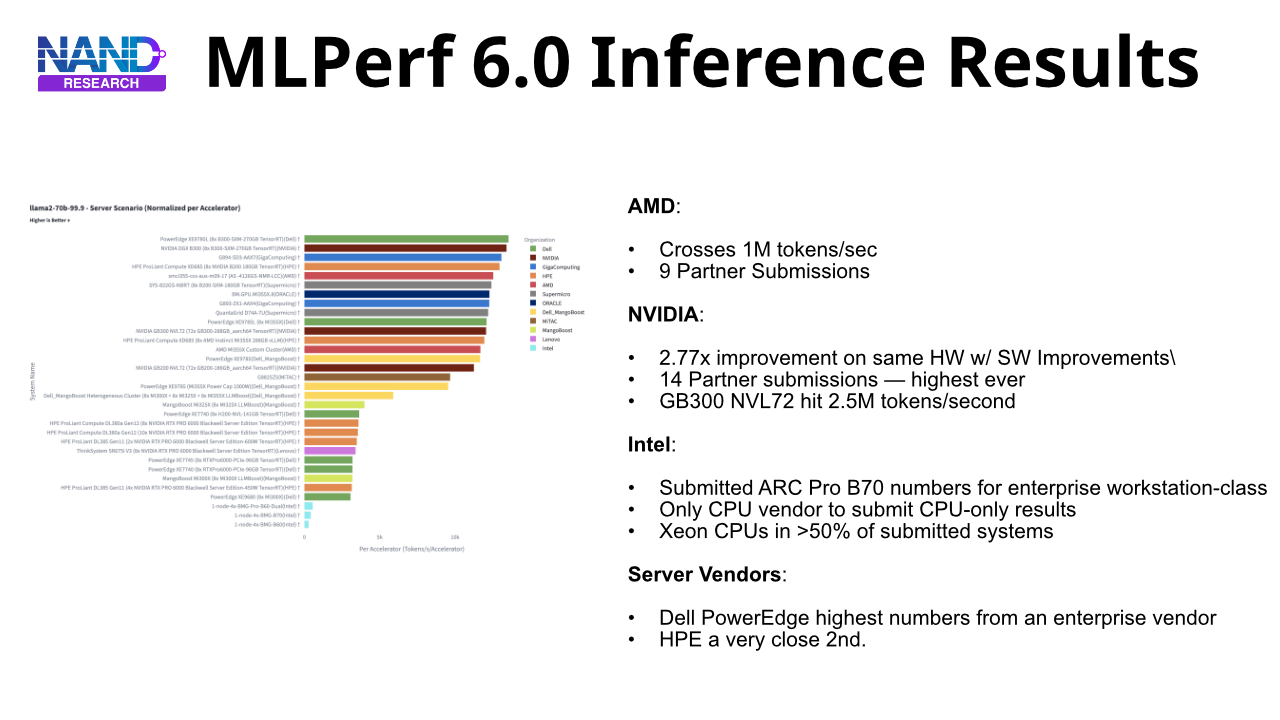
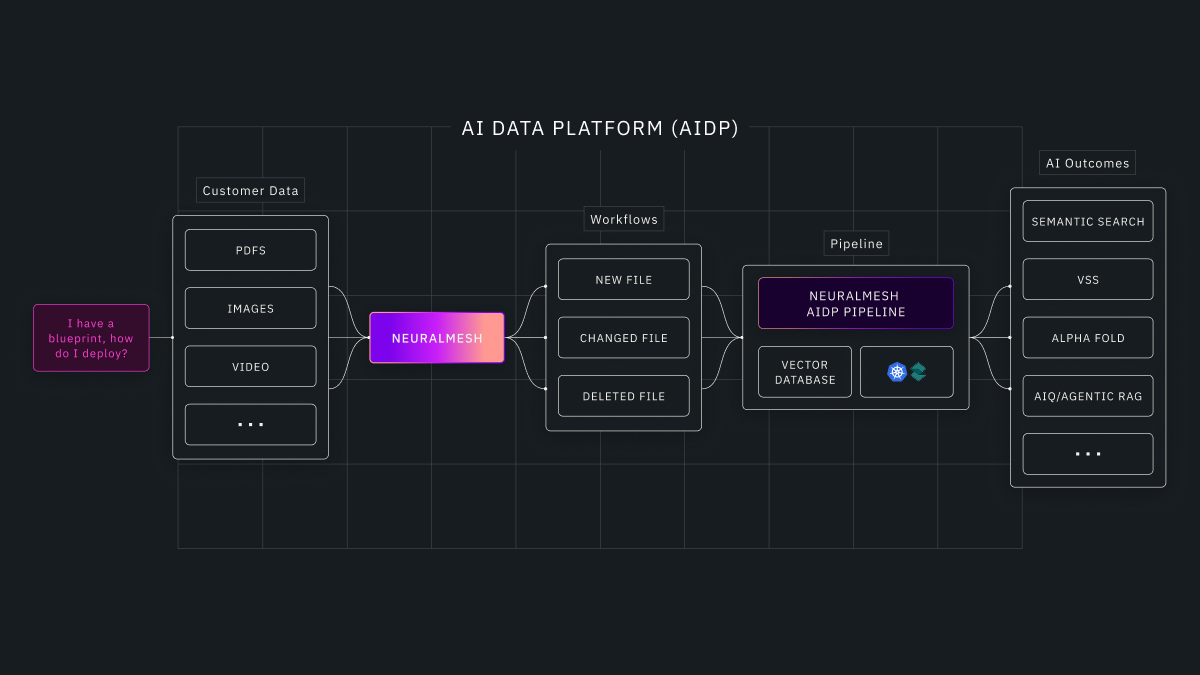
VAST Data announced support for NVIDIA’s recently unveiled Inference Context Memory Storage (CMX) Platform, targeting the NVIDIA Rubin GPU architecture. The announcement addresses the challenge of managing KV cache data that exceeds GPU and CPU memory capacity as context windows scale to millions of tokens across multi-turn, agentic AI workflows.
While NVIDIA’s CMX architecture is centered on using its BlueField-4 DPU as a control point in connecting to external storage, VAST takes things further.
VAST’s implementation runs its CNode storage software directly on NVIDIA’s BlueField-4 DPU, eliminating the need for dedicated external storage controllers.
VAST’s Disaggregated, Shared Everything (DASE) architecture makes this approach possible, providing parallel, contention-free access to shared storage across all GPU hosts in a cluster.
Technical Details
VAST supports NVIDIA’s CMX Platform with fundamental changes to where storage services execute and how data moves through the system. Rather than dedicating separate storage server or dedicated external storage arrays, VAST runs its CNode (CNode is VAST’s software-defined storage controller) directly the NVIDIA BlueField-4 DPUs integrated into each GPU server.

This consolidation relocates data management services from external storage arrays to the compute infrastructure where inference actually executes.
The implications of this consolidation are substantial. Each GPU server’s BlueField-4 DPU provides the CPU cycles necessary to run the complete VAST storage stack, including placement decisions, access enforcement, and metadata resolution.
VAST estimates its appraoch achieves a 75% reduction in power consumption for KV cache operations compared to more traditional approaches. While the estimate sounds plausible, it’s impossible validate as NVIDIA’s Vera Rubin is not yet available in production environments.
The data path optimization extends beyond server consolidation. VAST implements zero-copy I/O operations using GPUDirect Storage combined with RDMA over NVMe-over-Fabrics.
This approach allows data to move directly from GPU memory to NVMe SSDs and back without intermediate copies through CPU memory or storage controller buffers, eliminating at least one (and potentially two) copy operations from the traditional storage data path. The latency reduction from eliminating these copies directly benefits TTFT metrics.
DASE Architecture and Parallel Access
The architectural foundation enabling VAST’s approach is its DASE design. In conventional enterprise NAS systems and parallel file systems, each storage server owns exclusive partitions of the filesystem namespace. It’s an ownership model requiring coordination between servers when clients access data across partitions, creating east-west traffic that limits scalability and introduces latency variability.
VAST’s DASE architecture operates differently. The system disaggregates storage services from storage media ownership.
Each CNode container running on a BlueField-4 DPU can access the complete storage namespace and all NVMe SSDs in the cluster without requiring coordination with other CNodes.
This parallel access model provides several characteristics relevant to KV cache workloads:
- Dedicated per-host bandwidth: Each GPU server effectively has its own storage controller with direct access to all cluster SSDs, eliminating competition for storage server resources.
- Zero east-west coordination: CNodes operate independently without inter-server communication for data access operations.
- Concurrent full-namespace visibility: All hosts see and can access the complete KV cache namespace simultaneously.
- Linear bandwidth scaling: Adding GPU servers adds proportional storage service capacity since each new BlueField-4 DPU contributes additional processing resources.
Analysis
NVIDIA’s CMX platform highlights broader trends in AI infrastructure evolution that extend beyond any single vendor’s solution. As inference workloads transition from experimental to production deployment at scale, infrastructure requirements are fundamentally changing:
- Convergence of storage and compute infrastructure is accelerating: running storage services on DPUs embedded in GPU servers is a step toward more integrated, purpose-built AI infrastructure platforms.
- Memory hierarchy for AI workloads is expanding beyond GPU and CPU memory: it now includes new persistent tiers with distinct performance and cost characteristics.
- Ecosystem requirements for production AI infrastructure are becoming more complex and interdependent: solutions increasingly require specific combinations of GPUs, DPUs, network fabrics, orchestration frameworks, and storage platforms.
VAST Data’s implementation of NVIDIA’s Inference Context Memory Storage Platform addresses a genuine infrastructure challenge created by the evolution of AI inference workloads toward longer contexts and more complex, multi-turn interactions.
The company’s approach of running storage services on BlueField-4 DPUs embedded in GPU servers delivers a compelling value proposition. VAST promises to eliminate traditional storage server infrastructure while providing parallel zero-copy access to shared NVMe storage.
VAST running its CNode software on a DPU isn’t new. The company first demonstrated the capability in 2023, running its stack on NVIDIA BlueField-3 DPUs. While its was an interesting solution when announced, the benefits have only grown. NVIDIA has released its more powerful BlueField-4 DPU, and the new CMX platform dramatically increases the potential value for AI practitiones.
NVIDIA’s CMX is tied to its Vera Rubin launch later this year. Early adopters of Vera Rubin will likely be hyperscalers and GPU-centric neoclouds. These are environments in which VAST Data is already experiencing strong success. Supporting NVIDIA CMX with VAST’s approach should be an easy lift for these customers. In the OEM-driven on-prem world, that will be a different, more competitive story.
Ultimately, VAST’s announcement is a meaningful advancement in how AI infrastructure handles the growing demands of inference context management. By treating KV cache as a first-class system resource and redesigning the storage architecture specifically for concurrent, shared access patterns at cluster scale, the platform addresses real limitations in current approaches.
The fundamental challenge VAST is addressing (efficiently managing massive, shared, continuously accessed inference context at scale) will only grow more critical as AI applications mature from experimental systems to production services handling millions of concurrent users with complex, long-lived interactions.
Competitive Outlook & Advice to IT Buyers
Nearly every mainstream storage vendor has announced support for the NVIDIA CMX platform. What distinguishes VAST Data is its ability to place its CNode directly into a BlueField-4 DPU. Despite its novelty and promise of increased performance and reduced latency, it may not be an option for everyone…
These sections are only available to NAND Research clients and IT Advisory Members. Please reach out to [email protected] to learn more.