At the recent GTC 2026, WEKA announced two major updates that enhance its position at the crossroads of AI storage and inference infrastructure. The company revealed the general availability of NeuralMesh AI Data Platform (AIDP), a ready-to-use appliance-style system based on the NVIDIA AI Data Platform reference design.
It also introduced the integration of its NeuralMesh software with the NVIDIA BlueField-4 STX reference architecture, featuring WEKA’s Augmented Memory Grid technology as the shared KV cache layer for the STX context memory tier.
Both announcements address ongoing bottlenecks in enterprise AI deployment: the gap between proof-of-concept and scaled AI Factory operations, and the inference-cost pressures caused by KV cache eviction and context loss under concurrent agent workloads..
The announcements also demonstrate WEKA’s dual strategy of targeting enterprise accounts with simplified deployment and less integration hassle, while also competing for hyperscale and AI cloud provider workloads through close NVIDIA architecture alignment.
Technical Details
WEKA’s announcements span two distinct but complementary technical domains:
- NeuralMesh AIDP addresses full-stack AI data platform deployment
- STX integration focuses specifically on inference-layer memory architecture and KV cache management.
Both are built on the NeuralMesh software foundation, which WEKA describes as built on more than 170 patents and a software-defined architecture that scales performance as the environment grows.
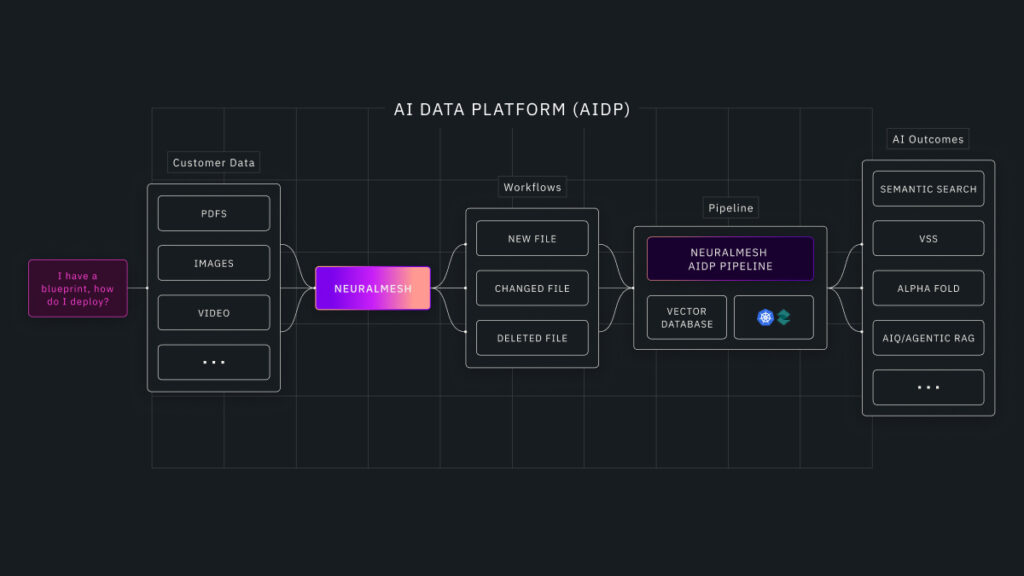
NeuralMesh AI Data Platform (AIDP)
The NeuralMesh AIDP is provided as an appliance-style system aligned with the NVIDIA AI Data Platform reference design. It is shipped as a pre-integrated package rather than a set of components requiring customer assembly, and is designed to reduce AI Factory deployment timelines.
The platform handles the continuous operational cycle of enterprise AI, including data ingestion, transformation, retrieval, and inference, all running simultaneously as data and models evolve.
NeuralMesh AIDP has the following capabilities:
- Ingestion and change detection across enterprise data sources, tracking creation, updates, and deletions to maintain AI-ready representations
- AI-ready transformation pipeline including parsing, chunking, enrichment, embedding generation, metadata tagging, and lineage tracking
- Integrated vector database layer with continuous index refresh, avoiding the retrieval staleness that builds up in static or batch-updated systems
- Policy-aware data readiness that carries security permissions and governance metadata through the pipeline
- Kubernetes orchestration via Spectro Cloud for deployment and day-two operations
- Integration with Red Hat OpenShift on a roadmap basis for consistent lifecycle management across on-premises and cloud environments
- Validated hardware configurations on Supermicro with NVIDIA RTX PRO 6000 Blackwell Server Edition and RTX PRO 4500 Blackwell Server Edition GPUs
The system supports pre-built AI application workflows tailored for specific vertical use cases, including semantic search, video search and summarization, AlphaFold for drug discovery, and AIQ agentic RAG pipelines. The AIDP uses an open-source vector database layer, avoiding locking customers into a closed vector dependency (a differentiator over competitors like VAST Data).
NeuralMesh & Augmented Memory Grid on NVIDIA STX
Its STX integration enhances WEKA’s Augmented Memory Grid technology with the NVIDIA BlueField-4 STX reference architecture, tackling the KV cache management challenge in large-scale agent inference.
As agentic AI workloads, especially software engineering applications, generate longer context windows and higher concurrency demands, on-GPU HBM becomes exhausted and KV cache must be evicted. This leads to recomputation of context that should be persistent, increasing inference costs and slowing response times.
Augmented Memory Grid handles this by pooling and storing the KV cache in a shared external memory tier spanning agents, users, and sessions.
The STX integration specifically introduces the following features:
- Deployment on NVIDIA Vera Rubin NVL72 architecture with BlueField-4 DPUs and Spectrum-X Ethernet networking
- WEKA claims 4 to 10 times more tokens per second for context memory workloads compared to architectures without shared KV cache
- WEKA claims at least 320 GB/s read and 150 GB/s write throughput for AI workloads, more than double conventional AI storage platform throughput
- BlueField-4 DPU integration offloads the storage data path from the CPU, keeping GPU cycles dedicated to inference computation
- Time-to-first-token improvements of 4 to 20 times under real-world concurrent load
- Serves 6.5 times more tokens per GPU without adding infrastructure
Augmented Memory Grid is commercially available with NeuralMesh today. The STX-specific integration targets the NVIDIA BlueField-4 and Vera Rubin architecture, extending prior validations that WEKA conducted with Supermicro on NVIDIA Grace CPUs and BlueField-3 DPUs.
Competitive Landscape
WEKA’s GTC 2026 announcements position it against a broad array of vendors in the storage and AI data platform markets. No competitor offers the same unique combination of an NVMe-over-Fabric distributed storage architecture, integrated KV cache management, and full-stack AI data platform packaging.
Customers considering WEKA will also consider alternatives from other vendors:
- NetApp, VAST Data, and Everpure (Pure Storage) each compete in high-performance AI storage, and all three have deepened NVIDIA integrations. VAST Data’s positioning as an AI data platform has the most direct overlap with WEKA’s AIDP, though VAST’s platform strategy centers on its database-like storage architecture rather than an appliance delivery model
- Dell and HPE offer pre-integrated AI infrastructure portfolios to the same enterprise buyers that WEKA targets with AIDP. These vendors provide broader service and support networks, which are important in enterprise accounts, where operational support commitments influence purchasing decisions.
- The KV cache management space is early but increasingly crowded. NVIDIA’s own CMX architecture within STX sets the reference design, and WEKA’s differentiation depends on Augmented Memory Grid performing better than alternative external KV cache approaches from storage and memory vendors who will target the same integration point
- MinIO and IBM also have NVIDIA AI Data Platform alignments, adding competition in the object storage and AI data pipeline layer for organizations that do not require NeuralMesh’s parallel file system performance characteristics
WEKA’s genuine differentiation in this competitive landscape rests on three factors:
- The maturity of its NVIDIA integration across multiple architecture generations,
- Augmented Memory Grid technology’s head start in shared KV cache infrastructure
- A software-defined architecture that scales performance with the environment rather than requiring hardware upgrades.
Whether these advantages hold as competitors close the NVIDIA integration gap and KV cache management becomes a more standardized infrastructure function is the central long-term question for WEKA’s enterprise success.
Final Thoughts
WEKA’s GTC 2026 announcements are technically coherent and aligned with the company’s strategic path. The NeuralMesh AIDP tackles a real issue: most enterprise AI projects show proof-of-concept success but fail to scale up to production because the data infrastructure was not built for continuous, concurrent, AI-specific workloads.
Providing the solution as a pre-integrated, appliance-style system instead of a reference architecture that requires assembly is the right approach for the enterprise buyer who lacks the capacity to act as its own systems integrator.
The STX integration and the Augmented Memory Grid KV cache economics argument are WEKA’s strongest competitive advantages. The idea that inference costs are determined by the memory infrastructure layer rather than the compute layer is convincing and increasingly backed by real-world deployment data.
WEKA’s GTC 2026 announcements collectively address the two most persistent challenges in enterprise AI deployment: deploying AI workloads into production and managing inference costs as those workloads grow.
Together, the announcements give WEKA a clear answer to both the enterprise IT buyer asking how to operationalize AI and the AI cloud provider asking how to lower cost per token at scale.