NVIDIA recently announced that Multipath Reliable Connection (MRC), an RDMA transport protocol developed for and in production on Spectrum-X Ethernet hardware, is now available to the broader industry via the OCP.
As clusters scale to hundreds of thousands of GPUs, standard Ethernet transport protocols lack the multipath awareness, congestion responsiveness, and failure-recovery speed needed to sustain efficient distributed training at that scale.
MRC addresses this structural limitation in AI training fabrics by allowing a single RDMA connection to distribute traffic across multiple network paths simultaneously, thereby enabling dynamic load balancing, real-time congestion avoidance, and microsecond-level path-failure recovery.
NVIDIA developed MRC in collaboration with AMD, Broadcom, Intel, Microsoft, and OpenAI. Publishing the specification through OCP extends the protocol’s reach beyond NVIDIA’s own hardware ecosystem, though the company expects its Spectrum-X implementation, backed by deep telemetry and fabric control, to remain the performance-optimized reference deployment.
Beyond the marketing launch, the contributing companies also released a technical paper, Resilient AI Supercomputer Networking using MRC and SRv6, describing the protocol and testing results.
What is MRC?
MRC extends the RoCE RC transport (the RDMA-over-Converged-Ethernet standard defined by the InfiniBand Trade Association) to enable true multipath operation. The central design decision is to shift responsibility for load balancing and failure handling from complex network switch control planes to the network endpoints, with end-to-end controls implemented in the NIC and host software stack.
Where standard RoCEv2 binds a queue pair to a single network path, MRC decouples the RDMA connection from path assignment, allowing a single connection to fan traffic across hundreds of paths simultaneously and to dynamically reassign paths based on real-time fabric conditions.
This is a deliberate architectural inversion relative to conventional Ethernet designs. In traditional fabrics, routing intelligence lives in the switches, and hosts have limited visibility into or control over how their traffic traverses the network.
MRC embeds routing logic at the host, enabling the endpoint to participate in path selection and congestion response. The network still provides feedback, but the host acts on it rather than waiting for the switch control plane to converge.
MRC builds on techniques developed by the Ultra Ethernet Consortium (UEC) and extends them with SRv6-based source routing to support large-scale AI networking fabrics. SRv6 (Segment Routing over IPv6) allows the host to specify the explicit path a packet should take through the network, with the path encoded directly in the packet header.
This enables hardware-deterministic routing without requiring dynamic switch protocols to compute paths on-the-fly, simplifying the switch control plane and giving the host precise control over traffic placement across the fabric.
Core Capabilities
MRC’s technical capabilities span four primary areas: multipath load balancing, congestion management, failure recovery, and telemetry.
Each addresses a distinct failure mode that becomes acute at the scale of frontier AI training clusters, where a single training step can involve millions of synchronous data transfers and a single delayed transfer can cause GPU idle time across thousands of nodes.
MRC delivers:
- Multipath packet spraying: MRC spreads individual packets for a single RDMA connection across hundreds of network paths simultaneously. This distributes traffic load across the full available fabric capacity rather than concentrating flows on a subset of paths, which is the primary source of hot spots in conventional single-path RoCEv2 deployments. Each packet can take a different path to the destination; the receiver reassembles them in order.
- SRv6 source routing: MRC uses SRv6 to give the host explicit control over packet path selection. Rather than relying on switch-level Equal-Cost Multipath (ECMP) hashing (which can create uneven load distribution across links) the NIC encodes the intended path in the packet header. This allows the host to steer traffic away from congested or failed segments without switch coordination, and it enables large operators to disable dynamic routing protocols in switches entirely, replacing them with static routes and reducing switch control-plane complexity.
- Real-time congestion-aware routing: MRC ingests high-frequency telemetry signals from the fabric, including congestion indicators, packet loss events, and per-path utilization. It uses them to adjust path selection in real time. The protocol does not wait for timeout-driven congestion-control mechanisms to respond; it proactively reroutes around overloaded links.
- Selective retransmission: When packet loss occurs, MRC retransmits only the lost packets rather than triggering window-based retransmission, which resends large blocks of data. This minimizes the bandwidth cost of recovery and reduces the impact of transient link faults on long-running training jobs.
- Microsecond hardware-failure bypass: MRC detects path failures at hardware speed and reroutes traffic within microseconds. Conventional network fabrics can take seconds or tens of seconds to stabilize after a link or switch failure, during which synchronized GPU training jobs stall.
- High-frequency telemetry: MRC includes a built-in continuous telemetry reporting network conditions (e.g., congestion signals, packet loss, and per-path utilization) at intervals fine enough to support microsecond-level routing decisions. Administrators also gain per-path traffic visibility for diagnosis and troubleshooting at scale.
Topology and Scale
A key architectural claim from OpenAI is that MRC’s multipath design enables a two-tier Ethernet switch topology to connect more than 100,000 GPUs, a configuration that conventional 800 Gb/s networks require three or four switch tiers to achieve.
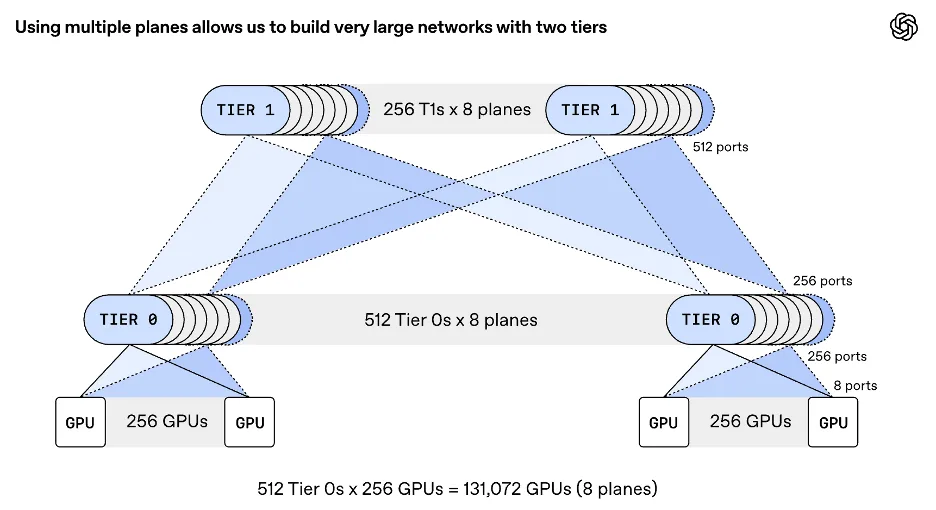
Reducing switch tiers lowers power consumption, component count, and network costs for clusters at this scale. This is due to MRC’s ability to exploit full fabric bandwidth across all available paths without creating the hot spots that force operators to add switch tiers for headroom.
MRC is also designed to integrate with multi-plane network architectures. A multiplane network deploys multiple independent Ethernet fabrics in parallel, with each plane providing a complete east-west path between all GPUs.
Spectrum-X hardware adds accelerated load balancing across planes, and MRC leverages multiplane awareness to route traffic intelligently across the parallel fabrics. When a plane degrades or requires maintenance, traffic shifts to adjacent planes without disrupting training jobs.
Hardware and Protocol Compatibility
MRC runs natively on NVIDIA ConnectX SuperNICs and Spectrum-X Ethernet switches, targeting the 800 Gb/s network interfaces deployed in the current GB200 generation of AI infrastructure. Spectrum-X supports MRC alongside its existing Adaptive RDMA transport, allowing operators to select, per workload, which transport protocol to run on the same physical hardware.
NVIDIA said in its announcement that other customer-specific transport variants are also supported, though it has not disclosed details.
The OCP specification publication makes the protocol available for third-party implementation. AMD, Broadcom, and Intel participated in MRC’s development, and their contributions are reflected in the specification.
Neither AMD nor Broadcom has announced a timeline or product roadmap for MRC-compatible NIC or switch implementations.
Until third-party hardware supports MRC, the protocol’s deployment remains tied to NVIDIA’s Spectrum-X ecosystem in practice, even as it carries the formal status of an open standard.
Analysis
MRC strengthens NVIDIA’s argument that Spectrum-X Ethernet is the production-grade network substrate for large-scale AI training. While InfiniBand dominated prior generations of HPC and AI cluster networking, NVIDIA has been methodically extending Spectrum-X Ethernet’s capabilities to match InfiniBand’s performance characteristics on Ethernet’s more familiar operational foundation.
MRC is the latest capability in that progression, and its validation by OpenAI and Microsoft in production frontier training environments carries substantial weight among other large AI infrastructure buyers.
Releasing the specification through the OCP publication is a strong strategic move. By making MRC an open specification with multi-vendor participation, NVIDIA counters the narrative that Spectrum-X Ethernet is a proprietary alternative to standard Ethernet.
The company maintains that its differentiation lives in silicon execution, software integration, and telemetry depth, not in closed wire formats. This is consistent with NVIDIA’s approach across its networking portfolio, which is based on open standards on the protocol layer, competitive differentiation in hardware and software implementation.
Competitive Landscape
The most directly relevant competitive context for MRC is the UEC, a multi-vendor initiative to define a new RDMA-based Ethernet fabric standard for AI workloads. UEC has attracted broad industry participation but remains a specification effort rather than a deployed technology.
NVIDIA’s ability to point to MRC running in production at large installations, such as those at Microsoft and OpenAI, creates a meaningful credibility gap between the two approaches.
Key competitors include:
- Ultra Ethernet Consortium: UEC is developing multipath and congestion-control capabilities for AI Ethernet fabrics, with participation from AMD, Intel, Broadcom, Cisco, and others. UEC’s multi-vendor governance makes it a better fit for organizations prioritizing vendor neutrality, but production deployments lag MRC by at least a product cycle. NVIDIA’s participation in UEC discussions provides visibility into the specification, while MRC offers a deployed alternative.
- InfiniBand: NVIDIA’s HDR and NDR InfiniBand remain the incumbent in the most performance-sensitive HPC and AI training environments. MRC narrows the gap between Ethernet and InfiniBand for large-scale AI use cases, and NVIDIA uses this to position Ethernet as a viable, operationally simpler alternative. The competitive risk is internal cannibalization, though NVIDIA manages this by targeting Spectrum-X Ethernet at AI factory scale and positioning InfiniBand for the highest-density HPC.
- Broadcom and Intel: Both companies participated in MRC’s development and are named as contributors to the OCP specification. Their position in the competitive landscape is nuanced, as they benefit from MRC as a protocol that runs on their NICs if they implement the spec, but they also compete with NVIDIA’s SuperNIC in the adapter market. Neither company has announced a timeline for MRC-compatible product availability.
- Custom cloud fabrics: Amazon Web Services, Google, and Meta operate proprietary AI networking fabrics tuned to their specific workloads. These are not generally available to third parties and are not directly competitive in the commercial market. However, their existence confirms that hyperscaler-scale AI workloads require network customization beyond what standard Ethernet provides, validating the problem space MRC addresses.
Impact for Practitioners
For infrastructure teams operating large-scale AI training clusters, MRC addresses problems that become acute only at scale. Standard RDMA transports over Ethernet, including baseline RoCEv2 implementations, rely on single-path routing that works adequately in smaller clusters but breaks down when thousands of GPUs compete for fabric bandwidth and when path failures create cascading stalls in tightly synchronized distributed training jobs.
MRC shifts the failure and congestion response from software-driven fallback to hardware-speed detection and rerouting, which changes the economics of running frontier training at scale.
Practical considerations for teams evaluating MRC on Spectrum-X include:
- Hardware dependency: MRC runs on ConnectX SuperNICs and Spectrum-X switches. Organizations with existing RoCEv2 infrastructure from other vendors cannot adopt MRC without hardware migration. The protocol is available through OCP, but interoperable third-party implementations are not yet commercially available.
- Control plane requirements: MRC extends routing logic to the host, so operators need host software stacks capable of participating in routing decisions. OpenAI built custom software to support this. Enterprise teams without dedicated network engineering resources face a steeper implementation path.
- Scale threshold relevance: MRC’s benefits are most pronounced at giga-scale, where multipath fabrics and microsecond-level failure response matter. Organizations running clusters with fewer than a few thousand GPUs may see limited incremental benefit over Spectrum-X with Adaptive RDMA.
- Telemetry and operational maturity: The fine-grained traffic visibility that MRC provides is valuable only if operations teams have the tooling and skills to act on it. This is an advantage for large hyperscalers and well-staffed infrastructure teams, but it adds operational complexity for smaller organizations.
Final Thoughts
NVIDIA’s MRC announcement pairs a credible technical capability with verified production deployments at the highest tier of AI infrastructure. The ability to reference OpenAI’s frontier LLMs trained on MRC, and Microsoft running it in its Fairwater AI factory, establishes Spectrum-X Ethernet as a proven platform for giga-scale AI (rather than a marketing alternative to InfiniBand).
NVIDIA has executed on the transition from conceptual capability to production-validated standard, which is the hardest part of establishing new networking infrastructure.
The open-specification approach via OCP is the right strategic move. AI networking at scale is becoming a systems problem, not a single-vendor problem, and customers at the frontier increasingly want protocol transparency even when they accept hardware specificity. By contributing MRC to OCP with involvement from AMD, Broadcom, and Intel, NVIDIA creates a credible ecosystem story while betting that its own silicon and software implementation will remain the highest-performance option.
The more significant long-term implication is what MRC reveals about the direction of AI networking. The protocol embeds routing intelligence at the host, blurring the boundary between compute and network management.
Organizations that own their infrastructure can leverage it to achieve deep, workload-specific optimization; hosted tenants on cloud platforms have less flexibility.
As AI workloads scale and training runs grow more expensive, the difference between a network that responds in microseconds and one that responds in milliseconds directly affects GPU utilization and training cost.
NVIDIA has made Spectrum-X Ethernet the reference implementation for that optimization, and MRC makes that position significantly harder to dislodge.