
NVIDIA announced its BlueField-4 STX reference architecture at GTC 2026, introducing a modular framework for deploying accelerated storage infrastructure optimized for agentic AI workloads. The architecture addresses a specific technical challenge: as AI systems evolve from single-turn interactions to complex, multi-step agentic workflows with context windows spanning millions of tokens, existing storage hierarchies struggle to efficiently manage the growing KV cache that stores an AI agent’s working memory.
The initial implementation of STX is NVIDIA’s CMX context memory storage platform, which introduces a new storage tier (called “G3.5”) between local node storage and shared enterprise storage.
The announcement also shows extensive industry support, with cloud providers (CoreWeave, Crusoe, IREN, Lambda, Nebius, OCI, Vultr) and AI companies (Mistral AI) planning to use STX for context memory storage.
Equally important is the involvement of storage vendors: DDN, Dell Technologies, Everpure, Hitachi Vantara, HPE, IBM, NetApp, Nutanix, VAST Data, WEKA, and others are co-developing next-generation infrastructure based on the STX reference architecture.
STX-based platforms are expected to be available from partners in the second half of 2026 as part of NVIDIA’s Vera Rubin roll-out.
The KV Cache Challenge
Transformer-based AI models maintain context through KV cache, a data structure that preserves computational state so models do not need to recompute history for every new token generated.
As context windows grow to millions of tokens to support agentic workflows, KV cache requirements increase proportionally, causing infrastructure challenges that current storage hierarchies were not designed to handle.
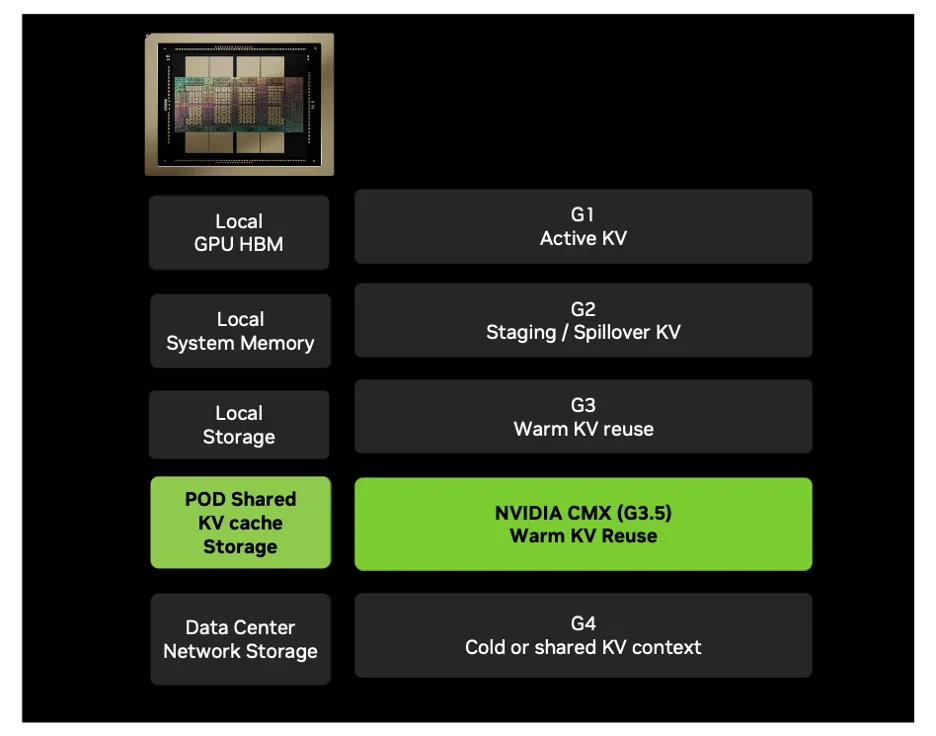
The current AI infrastructure storage hierarchy functions across four levels, each with unique features:
- G1 (GPU HBM): Nanosecond-scale access for active KV cache used in token generation. Highest efficiency but severely capacity-constrained.
- G2 (System RAM): Staging and buffering tier for KV cache overflow from HBM. Higher latency than G1 with moderate capacity.
- G3 (Local SSDs): Warm KV storage for shorter-timescale reuse. Node-local architecture creates management complexity and scaling limitations.
- G4 (Shared Storage): Enterprise-grade networked storage optimized for durability, data protection, and capacity. Millisecond-level latency makes it unsuitable for active inference context.
G1-G3 tiers are optimized for quick access but have limited capacity; G4 is designed for durability and larger capacity but causes unacceptable latency during active inference.
KV cache is essential for performance but inherently temporary and re-computable, so traditional enterprise storage features (replication, consistency checks, metadata management) are unnecessary overhead for this data type.
STX Reference Architecture
NVIDIA STX is a modular reference architecture that combines compute, networking, and storage into configurable rack-scale building blocks. The architecture will be delivered as part of the upcoming NVIDIA Vera Rubin platform and unifies several NVIDIA technologies into a single storage infrastructure.
Core components of the STX architecture include:
- BlueField-4 Processor: Storage-optimized data processing unit that combines the Vera CPU with ConnectX-9 SuperNIC. Offers ultra-high-speed connectivity, integrated multi-core processing, high-bandwidth memory, and hardware acceleration engines for line-rate encryption and CRC-based data protection.
- Spectrum-X Ethernet: AI-optimized networking fabric offering RDMA-based connectivity. Includes adaptive routing, advanced congestion control, and optimized lossless RoCE to reduce jitter and tail latency under heavy load.
- DOCA Framework: Software stack featuring the new DOCA Memos framework for KV communication and storage, with context cache managed as a first-class resource for management, sharing, and placement.
- NVMe and NVMe-oF Transport: Standard storage protocols, including NVMe KV extensions, ensure interoperability with existing storage infrastructure.
CMX Context Memory Storage Platform
CMX is the first rack-scale implementation of the STX architecture, establishing a new “G3.5” storage tier between local node storage (G3) and shared enterprise storage (G4).
The platform is built on Ethernet-connected flash storage and operates at the pod level, offering shared access to KV cache across all nodes within the pod.
Key technical capabilities:
- Capacity: Petabytes of shared capacity per GPU pod, enabling long-context workloads to retain history after eviction from HBM and DRAM.
- Prestaging: KV blocks can be moved from CMX into G2 or G1 memory ahead of the decode phase, reducing decoder stalls and GPU idle time.
- Shared Access: Context becomes a shared, high-bandwidth resource that orchestrators can coordinate across agents and services without rematerializing independently on each node.
- Hardware Acceleration: BlueField-4 crypto and integrity accelerators secure and validate KV flows without adding host CPU overhead, running encryption and CRC at line rate.
Software Integration
CMX integrates with NVIDIA’s inference orchestration stack through several software components:
- NVIDIA Dynamo manages inference context movement across memory and storage tiers, using CMX as the context memory layer.
- NVIDIA Inference Transfer Library (NIXL) handles KV block transfers between tiers.
- Grove provides topology-aware workload placement with KV locality awareness, enabling workloads to continue reusing context even when moving between nodes.
- DOCA Memos provides open interfaces for storage partners to integrate their solutions with the G3.5 context tier.
Impact Analysis
Impact on Practitioners
For AI infrastructure teams deploying agentic systems at scale, STX/CMX tackles a real operational challenge. Managing KV cache across current storage hierarchies demands complex orchestration, and the gap between ephemeral context data and durable enterprise storage causes efficiency losses that grow as scale increases.
Operational benefits:
- Simplified Architecture: A dedicated tier for KV cache removes the need to repurpose general-purpose storage for ephemeral inference context, potentially lowering configuration complexity.
- GPU Utilization: Reliable pre-staging of context into GPU memory before decode operations should decrease idle cycles, though actual utilization gains will depend on workload characteristics.
- Power Efficiency: AI factories encounter strict power limits. If the claimed efficiency gains are confirmed in real-world use, this directly allows for more compute capacity within current power constraints.
- Shared context: Pod-level KV sharing across nodes can decrease duplicate context calculations, especially important for multi-agent systems that need to share working memory.
Market Positioning
STX broadens NVIDIA’s platform approach beyond compute and networking to include specialized storage solutions. This marks a significant expansion for the company, positioning NVIDIA not just as a GPU provider but as the creator of comprehensive AI infrastructure that covers compute, networking, and now storage layers.
Strategic differentiation:
- Full-Stack Control: By establishing the reference architecture from GPU to storage, NVIDIA can optimize the entire inference process instead of relying on third parties for storage integration (and, conversely, innovation)
- New Data Class Definition: NVIDIA explicitly characterizes KV cache as an “AI-native data class” separate from enterprise data, thereby justifying purpose-built infrastructure instead of adapting existing storage.
- Partner Ecosystem Engagement: Instead of competing directly with storage vendors, NVIDIA positions STX as a reference architecture for partners to develop on, promoting collaborative rather than competitive relationships.
- Vertical Integration Revenue: BlueField-4 processors and Spectrum-X networking add more NVIDIA hardware to each STX deployment, increasing average revenue per AI factory.
Impact on Storage Vendors
The storage industry’s response to STX will determine whether this leads to a collaborative market expansion or causes competitive tension. The broad participation of major storage vendors in the initial announcement suggests the former, but strategic implications need careful analysis.
Opportunities:
- New Market Category: STX creates a distinct infrastructure tier that represents a net-new revenue opportunity rather than cannibalization of existing storage business.
- Differentiated Offerings: The reference architecture model allows vendors to add value through implementation and integration services, as well as software differentiation beyond NVIDIA’s baseline.
- G4 Tier Preservation: CMX is explicitly positioned as complementary to enterprise storage (G4), allowing traditional storage vendors to maintain their role in durable data management.
- Early Access: Participating vendors gain early access to AI infrastructure requirements and can influence the category’s evolution.
Risks:
- Reduced Differentiation: As a reference architecture, STX defines the implementation blueprint, potentially commoditizing vendor contributions and limiting margin opportunities.
- NVIDIA Dependency: Storage vendors become dependent on NVIDIA’s hardware roadmap and architectural direction for the G3.5 tier, reducing strategic independence.
- Investment Requirements: Building STX-based offerings requires engineering investment and potential restructuring of product portfolios, with uncertain return timelines.
Final Thoughts
NVIDIA’s STX reference architecture and CMX context memory storage platform directly address a real infrastructure challenge faced by organizations deploying large-scale AI. The key insight is that KV cache is a unique type of data that neither high-speed GPU memory nor durability-focused enterprise storage manages efficiently. Building a dedicated tier for this workload solves actual inefficiencies in current AI infrastructure.
The broader importance goes beyond just the technical value. NVIDIA is setting the category standards and architectural patterns for AI context storage before alternatives emerge. The wide participation from cloud providers, AI providers, and storage vendors at launch indicates that the market agrees with both the problem definition and NVIDIA’s proposed solution framework.
Early adopters like CoreWeave, Crusoe, Lambda, Mistral AI, and Oracle Cloud Infrastructure offer influential reference deployments that will influence broader market perception.
For storage vendors, STX offers both opportunity and strategic challenges. The opportunity is in a new infrastructure category with fresh revenue potential that complements, rather than replaces, the existing enterprise storage market. The challenge comes from creating differentiated offerings within NVIDIA’s modular blueprint while managing increasing reliance on NVIDIA’s roadmap across compute, networking, and now storage infrastructure.
For AI infrastructure practitioners assessing these developments, the key factor is timing. STX-based platforms will not be widely available until the second half of 2026, allowing time to evaluate production performance data from early adopters before making infrastructure decisions.
Organizations planning Vera Rubin deployments should start engaging with NVIDIA and partner vendors to understand integration options and roadmaps, while those with existing infrastructure should assess whether current storage solutions can meet KV cache scaling needs in the meantime.
As AI systems progress toward persistent, agentic architectures with growing context needs, storage infrastructure must also develop. NVIDIA positions itself as the architect of this change, expanding its platform influence from compute and networking into storage.
Whether this signifies a sustainable expansion or overreach depends on execution, partner collaboration, and the overall trajectory of agentic AI adoption. For now, STX positions NVIDIA as the first mover in defining what AI-native storage infrastructure entails, providing a significant advantage in an emerging market category.



