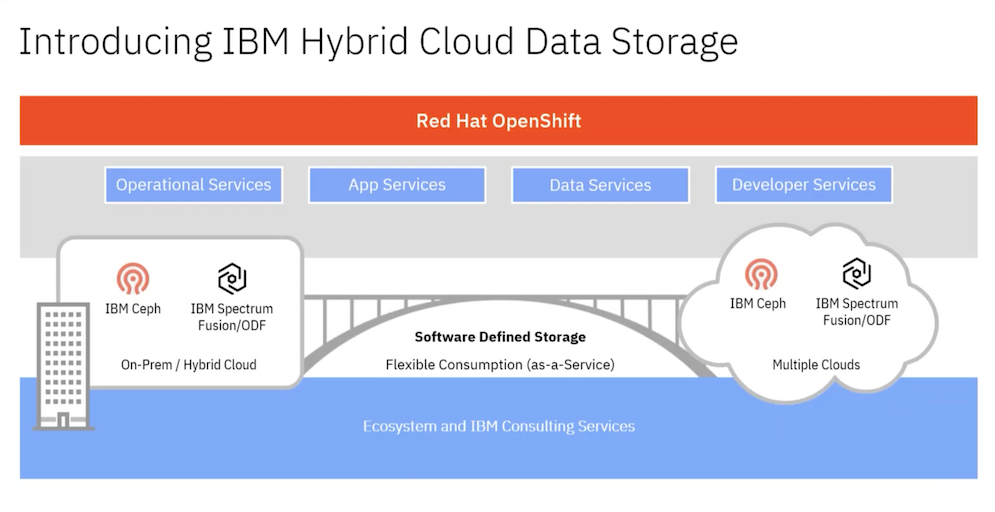
It’s been about a year since IBM brought Red Hat’s OpenShift Data into the IBM Storage group. In that time, IBM has focused on addressing data challenges in AI scaling and the storage requirements to support the rapidly growing data, along with various formats and locations, within the modern hybrid-cloud enterprise.
This journey involves modernizing infrastructure with solutions that deliver consistent application and data storage across on-premises and cloud environments and adopting cloud-native architectures for public cloud benefits like cost, speed, and elasticity.
IBM Storage Ceph, formerly Red Hat Ceph, is an open-source, software-defined storage platform that plays a vital role in this effort. It offers flexibility and scalability that are suitable for modern use cases like generative AI.
By abstracting storage resources from the hardware, IBM Storage Ceph allows dynamic allocation and efficient data storage utilization. This unified file, block, and object storage platform is self-healing and self-managing, designed to work on standard hardware.
IBM Storage Ceph addresses the growing unstructured data and generative AI needs, with Gartner predicting a significant increase in unstructured data capacity by 2028. IBM Storage Ceph’s scalability and self-managing features are critical for managing large volumes of data and meeting the demands of cloud-scale capacity management and deployment.
IBM’s approach includes consuming storage services on-prem with a cloud-native model to address enterprise needs, data sovereignty, and cost considerations. IBM Storage Ceph integrates easily with various infrastructures, cloud environments, hypervisors, and data repositories. It supports the seamless integration of new nodes or devices, making it an efficient choice for building data lakehouses and supporting AI workloads.



