Over the past several years, “Apache Iceberg support” has quietly become table stakes in modern data infrastructure conversations. Storage vendors list it in press releases, lakehouse platforms lead with it and architects assume it.
But here’s the reality: “supports Iceberg” can mean very different things depending on what layer of the stack you’re talking about.
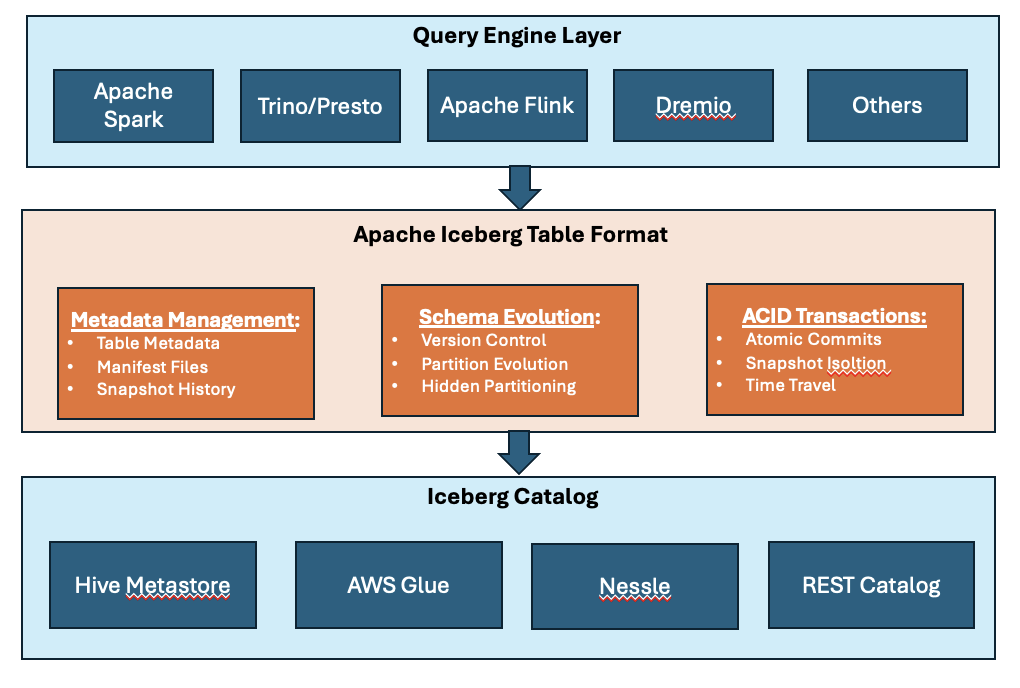
For IT buyers, clarity matters. Iceberg is not just a file format. It’s a table abstraction layer with metadata management, versioning semantics, and operational requirements. Supporting Iceberg properly involves three distinct capabilities:
- Storage for Iceberg data and metadata files
- Catalog services
- Table maintenance features
As Apache Iceberg adoption grows, more storage vendors claim “Iceberg support.” But that phrase can mask very different architectural responsibilities.
For IT buyers, the distinction between native and non-native support has real implications for:
- Operational complexity
- Failure domains
- Staffing requirements
- Performance consistency
- Long-term cost
To understand those implications, it helps to walk through the three core layers of Iceberg support and examine what changes when support is native versus external.
Let’s unpack each, and why they matter.
Storage for Iceberg Data and Metadata Files
Iceberg organizes table data using multiple types of files that must remain consistent and durable over time. To support this, Iceberg tables consist of:
- Data files (typically Parquet, ORC, or Avro)
- Manifest files
- Snapshot metadata files
- Versioned metadata trees
Because Iceberg performs atomic commits and tracks table versions through metadata references, the storage layer must handle not just large data files, but also frequent metadata updates and very high object counts.
What “native storage support” implies
When a vendor provides native storage support for Iceberg, the storage system is intentionally engineered and validated for Iceberg workloads. In practice, that often means the platform is:
- Designed for high object counts and small file workloads
- Strongly consistent (critical for atomic commits)
- Optimized for metadata-heavy patterns
- Tested explicitly under Iceberg workloads
Additionallly, vendors offering native support may publish performance guidance, tuning recommendations, or validated lakehouse reference architectures specific to Iceberg.
Implications of native storage support
When storage support is native, several operational advantages tend to follow, typically including:
- More predictable commit behavior under concurrent writers
- Lower risk of metadata bottlenecks at scale
- Fewer latency spikes caused by small-object inefficiencies
- Reduced need for deep storage-level tuning
From an operational standpoint, this means the storage team spends less time diagnosing issues that surface at the table layer but originate in object or filesystem behavior.
What “non-native” storage support looks like
In contrast, non-native storage support generally means the vendor provides S3 or POSIX compatibility, and Iceberg runs on top of that interface without deeper optimization. In these scenarios, the system may work correctly, but it may not have been purpose-built or validated specifically for Iceberg’s metadata patterns.
Implications of non-native storage support
When storage support is non-native, the responsibility shifts more heavily toward the IT organization. Common implications include:
- A higher architectural validation burden on internal teams
- Greater risk of scaling surprises at very high object counts
- Increased reliance on engine-level retries and compensating logic
- Potential migration risk if performance ceilings appear later
Non-native support does not automatically mean poor performance. However, it does mean that more of the performance envelope and failure testing falls on your team rather than the vendor.
Catalog Services (The Coordination Layer)
Iceberg separates physical storage from metadata coordination. The catalog acts as the coordination layer and is responsible for managing table locations, snapshot versions, schema evolution, and atomic commits.
Common catalog implementations in production environments include:
- Hive Metastore
- AWS Glue
- Project Nessie
- Iceberg REST catalog
- Databricks Unity Catalog
- Snowflake Polaris
Because the catalog coordinates commits and prevents write conflicts, it becomes a critical availability and reliability component.
Native catalog support
Native catalog support means the storage vendor provides its own Iceberg-compatible catalog implementation, often via a REST interface, and tightly integrates it with the storage layer.
Implications of native catalog support
When the catalog is native to the platform, the architecture is typically simplified, resulting in:
- Unified identity and access control
- Fewer network hops during commit operations
- Reduced cross-service coordination
- Lower infrastructure footprint
With fewer independent services, the overall failure domain may shrink. There are fewer components to patch, scale, monitor, and secure independently.
However, native catalog support can also introduce tradeoffs. These may include:
- Increased dependence on the vendor’s roadmap
- Potential concerns about portability
- Reduced flexibility compared to best-of-breed external catalogs
In short, native catalog support simplifies operations but may concentrate architectural control.
Non-native (external) catalog integration
In many environments, the catalog is external to the storage platform. The storage system hosts the Iceberg files, while the catalog runs independently.
Implications of non-native catalog support
Using an external catalog provides architectural flexibility. This flexibility often enables:
- Independent scaling of storage and catalog services
- Easier multi-cloud or hybrid deployments
- Broader engine compatibility
At the same time, this flexibility introduces additional operational overhead. Organizations must now manage:
- Catalog high availability and backup
- Metadata database scaling
- Cross-region replication
- Upgrade compatibility testing
The net effect is a larger architectural surface area and potentially greater blast radius during outages. In multi-engine environments, catalog reliability becomes mission-critical.
Table Maintenance and Lifecycle Management
Iceberg tables do not automatically optimize themselves. Over time, unmanaged tables accumulate small files, stale snapshots, and orphaned objects. Without proactive maintenance, performance degrades and storage costs rise.
The most common lifecycle operations required for healthy Iceberg tables include:
- Compaction (rewriting small files into larger ones)
- Snapshot expiration (removing older versions safely)
- Orphan file cleanup
- Manifest rewrites
- Data clustering or sort optimization
This layer is often where real-world operational friction appears.
Native maintenance support
Native maintenance support means the storage or platform layer provides built-in lifecycle automation for Iceberg tables.
Implications of native maintenance support
When lifecycle management is automated, organizations often benefit from:
- Policy-driven compaction
- Automated snapshot expiration
- Continuous table optimization
- Integrated health monitoring
These capabilities tend to produce more consistent long-term performance and reduce operational toil. Over time, automated lifecycle management helps prevent table entropy and cost creep.
That said, native maintenance features may be opinionated. They may offer less granular control compared to fully custom Spark-driven maintenance workflows.
Non-native maintenance (engine-driven)
In many Iceberg deployments, maintenance is handled by query engines or external orchestration tools. For example, Spark jobs may perform compaction and cleanup on a scheduled basis.
Implications of non-native maintenance support
Engine-driven maintenance provides flexibility and customization. This flexibility allows organizations to:
- Tailor compaction strategies by workload
- Integrate maintenance into CI/CD pipelines
- Align lifecycle policies with governance frameworks
However, this approach increases operational complexity, requiring teams to manage:
- Scheduling logic
- Failure handling and retries
- Monitoring and alerting
- Governance safeguards against accidental data loss
Without disciplined oversight, tables degrade gradually and unpredictably.
A More Precise Definition of “Iceberg Support”
When evaluating storage platforms, IT buyers should translate “Iceberg support” into three concrete questions:
- Does the platform reliably store Iceberg data and metadata files at scale?
- Does it provide or tightly integrate with a production-ready catalog?
- Does it automate table lifecycle management, or must my team build and operate that layer?
The critical question is ultimately operational: If something breaks at 2:00 a.m., who owns diagnosing and fixing it? Is it the vendor, or your team?
That answer will often determine whether native or non-native Iceberg support aligns best with your organization’s operational model.




