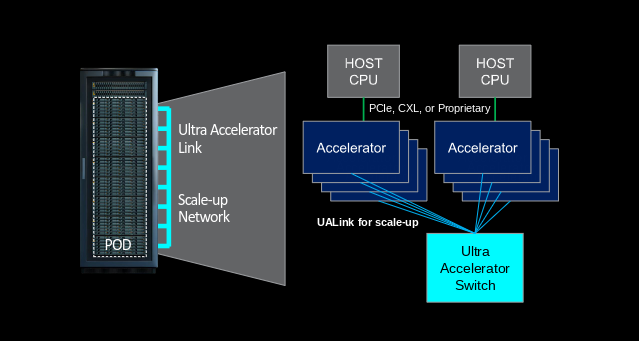
The UALink Consortium recently released its Ultra Accelerator Link (UALink) 1.0 specification. This industry-backed standard challenges the dominance of NVIDIA’s proprietary NVLink/NVSwitch memory fabric with an open alternative for high-performance accelerator interconnect technology.
Technical Overview & Key Features
UALink combines elements from PCI-Express, AMD’s Infinity Fabric, and modified Ethernet SerDes to create a purpose-built interconnect for accelerator memory fabrics.
The consortium, which includes AMD, Broadcom, Cisco, Google, HPE, Intel, Meta, and Microsoft, has focused the specification on optimizing for the specific needs of AI workloads.
Physical Layer Specifications
- Lane Speed: 212.5 GT/sec signal rate delivering 200 Gb/sec effective bandwidth per lane after encoding overhead
- Port Configuration: Supports x1, x2, and x4 lane configurations per port
- Maximum Port Bandwidth: 800 Gb/sec per port (using 4 lanes)
- Physical Transport: Modified Ethernet SerDes compliant with IEEE P802.3dj specification
- Error Handling: Forward Error Correction (FEC) with one-way and two-way code word interleaving
- Flow Control: 680-byte flit (flow control unit) as the atomic data unit at link level
Protocol Features
- Memory Operations: Optimized for simple memory reads/writes and atomic operations
- Ordering Relaxation: Removes PCI-Express ordering constraints, maintaining order only within 256-byte boundaries
- Fabric Scale: Supports up to 1,024 accelerators in a single-level fabric
- Deterministic Performance: Claims 93% effective peak bandwidth utilization
- Latency: Expected port-to-port hop latencies between 100-150 nanoseconds
Efficiency Metrics
- Die Area: 1/2 to 1/3 the silicon area of equivalent Ethernet ASICs
- Power Efficiency: Estimated 150-200W power savings per accelerator in a memory fabric
- Implementation Timeline: Expected to reach market in 12-18 months
Competitive Position
UALink is positioned between proprietary solutions and existing open standards:
- vs. CXL: UALink offers greater bandwidth, better accelerator scaling, and optimized memory fabric semantics
- vs. NVLink: Comparable performance with multi-vendor interoperability and standard implementation
- vs. Ethernet: Substantially lower latency and higher determinism for specialized accelerator communications
| Attribute | Current PCI-E/CXL Environment | UALink | NVLink |
| Bandwidth | Up to 128 GB/s (PCIe 6.0 x16) | Up to 200 GB/s (800 Gb/s port) | Up to 200 GB/s (NVLink 5.0) |
| Latency | 70-250 ns (switch hop) | 100-150 ns (projected) | Approx. 100 ns |
| Scale | Limited by PCIe switch radix | Up to 1,024 accelerators | Up to 576 GPUs (theoretical) |
| Software Adaptation | N/A | Requires memory fabric support | CUDA-optimized |
| Vendor Lock-in | Minimal | Minimized | High |
Impact to IT Organizations
UALink offers several potential benefits for organizations building AI infrastructure:
Deployment Flexibility
- Multi-vendor accelerator support enables heterogeneous computing environments
- Interoperability between different accelerator types (GPUs, NPUs, FPGAs)
- Potential consolidation of networking infrastructure
Economic Considerations
- Capital Expenditure:
- Lower ASIC complexity may reduce switch costs
- Freedom to mix accelerator vendors could improve price competition
- Potential reuse of existing rack designs with UALink switches
- Operational Expenditure:
- Power reduction claims of 150-200W per accelerator significantly impact datacenter TCO
- Reduced cooling requirements in high-density AI clusters
- Simplified provisioning with standardized interconnect
IT organizations evaluating accelerator interconnects should:
- Monitor UALink implementation progress through 2025-2026
- Include interconnect capabilities in accelerator evaluation criteria
- Prepare for multi-vendor AI infrastructure as UALink matures
Analysis
UALink has potential to reshape the AI accelerator interconnect market, particularly if:
- Early implementations demonstrate claimed performance advantages
- Large cloud providers drive adoption through procurement requirements
- Software frameworks evolve to become more interconnect-agnostic
The quick release of the UALink 1.0 specification represents the most significant challenge to NVIDIA’s interconnect dominance since the rise of large-scale AI training. While actual market impact remains uncertain pending commercial implementation, the specification’s technical merits and broad industry backing show genuine potential to impact the AI accelerator interconnect market.
Organizations planning AI infrastructure investments should closely monitor UALink developments through 2025-2026 as early implementations reach the market.




