NVIDIA GTC 2025: The Super Bowl of AI
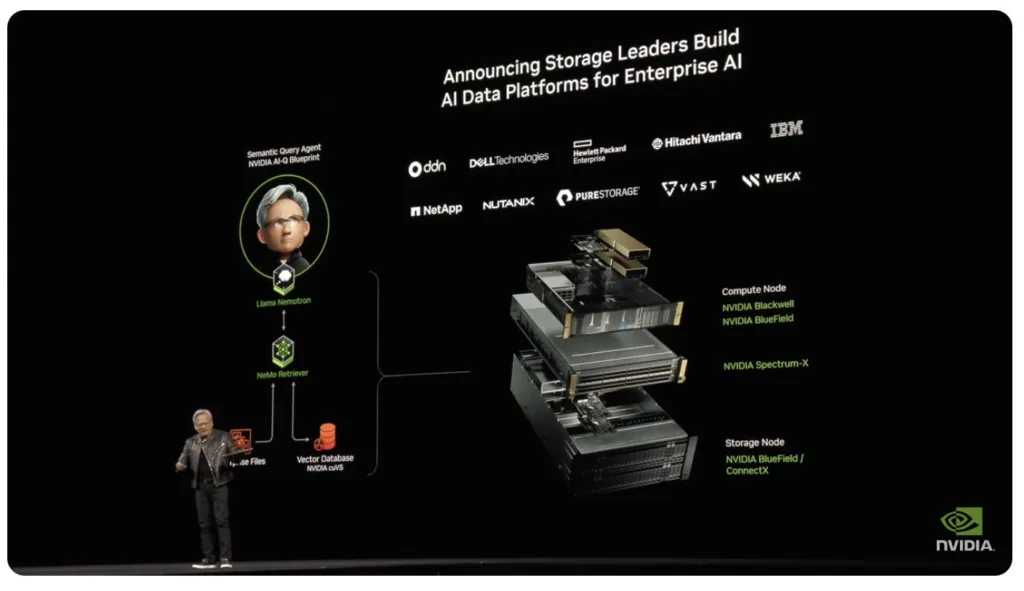
If you thought AI was already moving fast, buckle up, Jensen Huang threw more fuel on the fire. NVIDIA’s GTC 2025 keynote wasn’t just about new GPUs; it was a full-scale vision of computing’s future, one where AI isn’t just a tool — it’s the foundation of everything.
Let’s look at what Jensen talk about during his 2+ hour keynote.
SC24: Shaping the Future of IT with High-Performance Computing and AI

Last week’s Supercomputing 2024 (SC24) conference in Atlanta brought together IT leaders, researchers, and industry innovators to unveil advancements in HPC and AI, with even a little quantum computing thrown in.
Research Note: Supermicro’s New Datacenter Scale Liquid Cooling

Supermicro recently announced a comprehensive, end-to-end liquid cooling solution for data centers. The solution encompasses critical hardware components such as Coolant Distribution Units (CDUs), cold plates, Coolant Distribution Manifolds (CDMs), cooling towers, and integrated management software.
Quick Take: VAST Data and Supermicro Collaborate on Scalable AI Solution
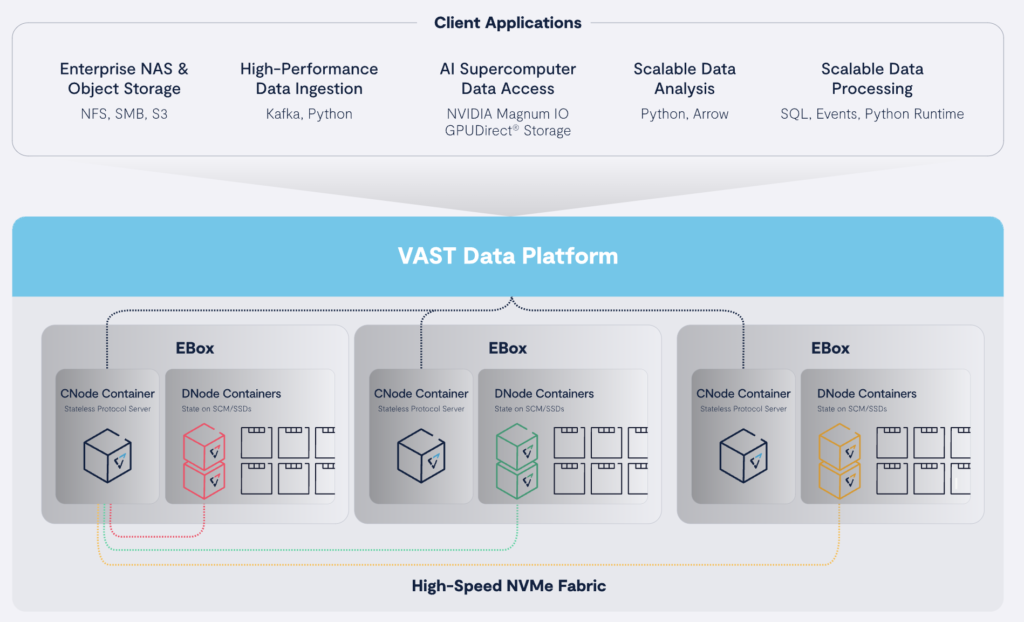
Supermicro/VAST Data’s new solution provides innovative parallel architecture and unified global namespace ensure optimal GPU utilization, scalability, and smooth data access from edge to cloud, eliminating the usual trade-offs between performance and capacity.