At its recent Discover event, HPE announced an expansion of its NVIDIA-based AI Computing portfolio with three distinct AI factory configurations targeting enterprise, service provider, and sovereign deployment scenarios.The offerings center on the upgraded HPE Private Cloud AI platform, which integrates NVIDIA Blackwell GPUs with HPE ProLiant Gen12 servers, custom storage solutions, and orchestration software.
HPE claims that the platform delivers turnkey AI infrastructure, addressing enterprise requirements for security, scalability, and operational simplicity.
The portfolio spans from single-rack enterprise deployments to multi-thousand-node configurations for service providers. HPE is positioning this as a response to organizations struggling with AI infrastructure complexity, though the actual deployment simplification remains to be validated in production environments.
Technical Overview
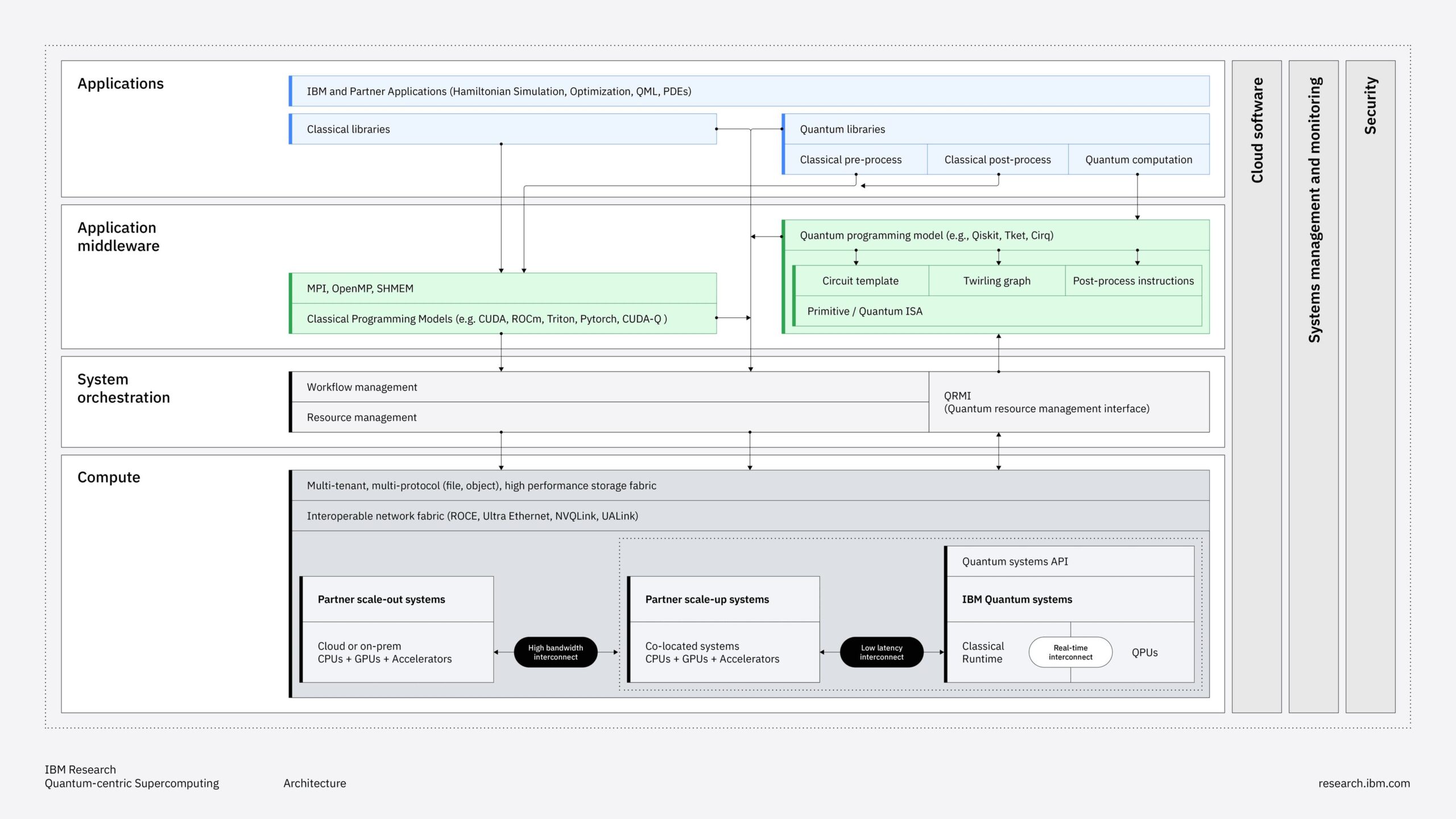
The HPE Private Cloud AI platform integrates multiple hardware and software components into a unified system. The core infrastructure comprises compute, storage, networking, and management layers that work together to provide enterprise-grade AI capabilities, including newly announced hardware platforms.
HPE Private Cloud AI Components:
- HPE ProLiant Compute Gen12 servers with NVIDIA Blackwell accelerated computing
- Support for NVIDIA H200 NVL and RTX PRO 6000 Server Edition GPUs
- HPE Alletra Storage MP X10000 with MCP server support
- NVIDIA AI Enterprise software stack, including AI Blueprints
- HPE Morpheus Enterprise Software for unified control plane
- HPE OpsRamp for full-stack observability
New Hardware Introductions
As part of the announcement, HPE introduced several new hardware platforms specifically for AI workloads. These new systems reflect the increasing demands of large language models and multi-modal AI applications.
HPE Compute XD690: This new compute node represents HPE’s highest-density GPU configuration, supporting eight NVIDIA Blackwell Ultra B300 GPUs in a single system. The XD690 addresses the growing compute requirements for model training and inference workloads that demand maximum GPU density per rack unit.
HPE ProLiant Compute Gen12 Servers: The latest generation of HPE’s server platform includes AI-optimized configurations with enhanced cooling capabilities and security features. These servers achieve HPE’s claimed 2X GPU acceleration performance improvement while maintaining enterprise-grade reliability and security standards.
HPE Alletra Storage MP X10000: This storage platform introduces MCP server support, specifically targeting agentic AI workloads that require high-throughput access to unstructured data. The X10000 integrates with NVIDIA’s AI Data Platform reference design and provides an SDK for streamlined data pipeline development.
Liquid Cooling Integration: HPE has integrated advanced liquid cooling technology across the AI factory portfolio, leveraging five decades of cooling expertise to address the thermal challenges of high-density GPU deployments. This cooling approach enables high-performance configurations while maintaining data center efficiency.
Management and Orchestration
HPE also introduced hardware-integrated management capabilities that extend beyond traditional server management to address the complexity of large-scale AI deployments.
HPE Performance Cluster Manager Integration: This management platform provides hardware-level monitoring and control across thousands of nodes, with specialized capabilities for GPU-intensive workloads. The system integrates directly with the hardware platform to provide real-time performance monitoring and automated resource allocation.
NVIDIA Blackwell Ultra GPU Support: The new hardware platforms are among the first to support NVIDIA’s latest Blackwell Ultra architecture, providing early access to next-generation GPU capabilities. This support encompasses both hardware optimization and software integration to maximize performance extraction.
Enhanced Security Hardware: The Gen12 servers feature hardware-level security enhancements, including secure boot capabilities, hardware root of trust, and support for post-quantum cryptography. These features address growing concerns about AI infrastructure security and regulatory compliance requirements.
The platform’s software architecture introduces several new capabilities that distinguish it from traditional compute infrastructure. These features address the specific challenges that organizations face when deploying AI at an enterprise scale.
Federated Resource Pooling: The platform implements unified resource allocation across GPU generations, enabling new compute capacity to be made available to existing workloads without requiring infrastructure redesign.
Multi-tenancy Capabilities: Enterprise-wide resource sharing with granular controls for data access, GPU quotas, and project permissions across organizational teams.
Air-gapped Deployment Options: Isolated network configurations for organizations with strict data sovereignty requirements, eliminating external network dependencies.
Modular Scalability: Expansion racks allow scaling from initial deployments to enterprise-wide implementations without architectural changes.
Impact to IT Organizations
HPE’s AI solutions offer several operational advantages for IT practitioners, though these benefits come with corresponding costs and implementation challenges. Organizations should carefully evaluate both sides of this equation when considering deployment.
Operational Benefits:
- Pre-integrated hardware and software stack reduces deployment complexity
- A unified management interface through HPE Morpheus eliminates multi-vendor tool requirements
- Performance Cluster Manager provides monitoring across thousands of nodes
- 75+ pre-validated AI use cases reduce proof-of-concept development time
The financial implications extend beyond initial capital expenditure to include ongoing operational costs and infrastructure requirements. HPE offers financing options to address some cost concerns, but the total cost of ownership requires careful analysis.
Competitive Outlook & Advice to IT Buyers
HPE’s positioning in the AI infrastructure market relies on several key differentiators that distinguish it from competitors. These advantages stem from the company’s enterprise heritage and established relationships, though they also create specific market positioning challenges…
This section is only available to NAND Research clients and IT Advisory Members. Please reach out to [email protected] to learn more.
Analysis
The expanded HPE-NVIDIA collaboration follows a clear trend: enterprises are demanding vertically integrated, validated stacks that minimize deployment complexity while retaining scalability and choice. This joint portfolio meets those demands with breadth and depth, though differentiation will depend on execution, support, and continued co-engineering across the AI lifecycle.
This update also strengthens HPE’s position in the broader “AI factory” ecosystem, competing with similar efforts from Dell, Lenovo, and hyperscalers, especially for customers seeking on-premises or sovereign AI infrastructure.
HPE’s approach to AI infrastructure balances enterprise accessibility (turnkey systems and ISV integrations) with hyperscale capabilities (multi-GPU systems, federated infrastructure, and sovereign support), a pattern increasingly demanded by organizations operationalizing AI beyond experimentation.
The company’s focus on security, modular growth, and AI-native observability further differentiates it from cloud-centric or DIY alternatives, aligning with customer needs around data governance, cost control, and ease of management.