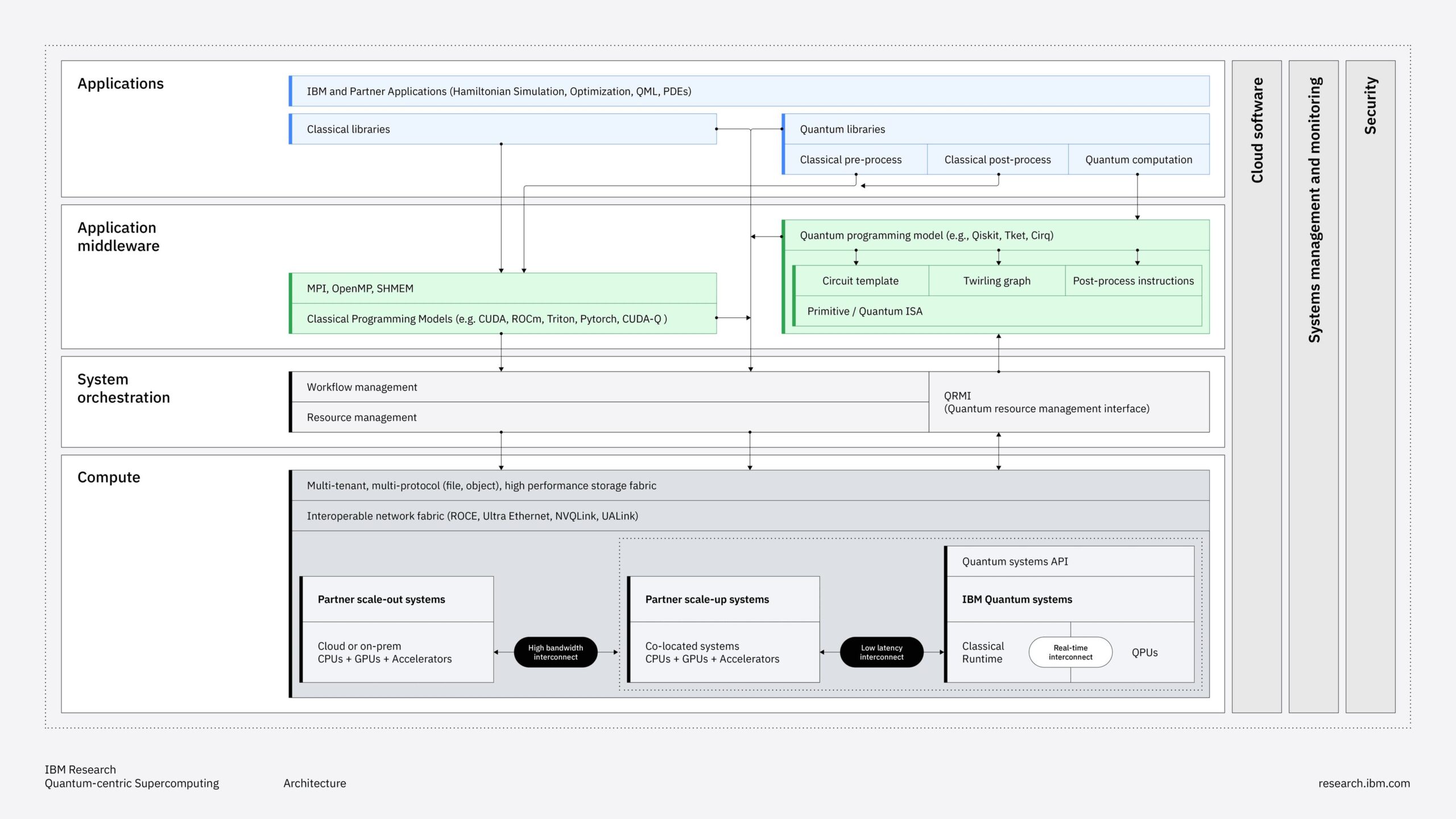
Qualcomm Technologies recently announced two data center inference accelerators, the AI200 and AI250, targeting commercial availability in 2026 and 2027, respectively. The products are Qualcomm’s first strategic push into rack-scale AI inference.
The AI200 offers 768 GB of LPDDR memory per card for large-language-model inference workloads. The AI250 introduces what Qualcomm characterizes as a “near-memory computing architecture,” which the company claims delivers over 10x the effective memory bandwidth of conventional approaches.
Both solutions integrate liquid cooling, support PCIe scale-up and Ethernet scale-out, and target 160 kW rack-level power consumption.
Simultaneously, Qualcomm announced a partnership with HUMAIN to deploy 200 megawatts of these solutions in Saudi Arabia starting in 2026.
The new products enter a market experiencing rapid diversification as enterprises seek alternatives to GPU-centric inference architectures based on total cost of ownership, power efficiency, and vendor independence considerations.
Technical Details
Qualcomm positions both accelerators as “purpose-built inference solutions” rather than general-purpose compute platforms, building on its neural processing unit (NPU) technology heritage from mobile and edge devices.
The architecture makes a deliberate tradeoff: optimizing for inference throughput and memory capacity while potentially sacrificing the flexibility that makes GPUs attractive for mixed training and inference workloads. This isn’t a limitation for Qualcomm’s targeted market.
AI200
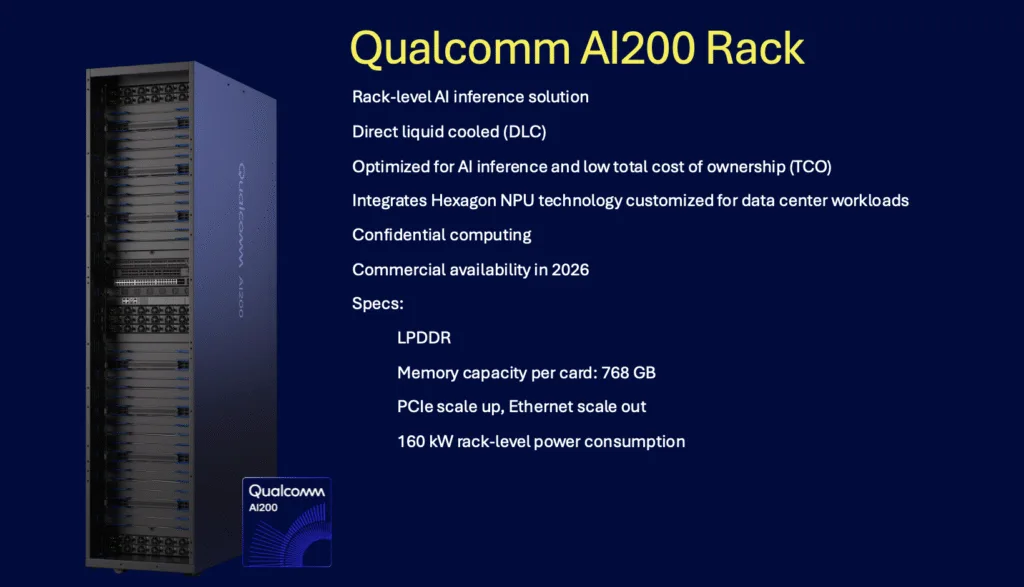
The AI200 targets immediate-term deployment, with memory capacity as its primary differentiator.
Key specifications include:
- Memory subsystem: 768 GB LPDDR per card, significantly exceeding comparable GPU memory configurations. This capacity targets multi-model serving scenarios and large-context-window applications where model weights and KV cache must remain resident in accelerator memory.
- Form factor: Available as standalone accelerator cards designed for retrofit into existing server infrastructure, lowering deployment barriers for organizations with installed server capacity and keeping the OEM on-prem market a viable channel for Qualcomm.
- Interconnect architecture: PCIe intra-rack scale-up enables multi-card configurations for larger models or higher-throughput requirements. Ethernet-based scale-out supports distributed inference across multiple racks (While Qualcomm has licensed NVIDIA nvLink interconnect technology, there is nothing in this announcement that points to its future usage.)
- Thermal management: Direct liquid cooling addresses the thermal density challenges of rack-scale AI deployment. This approach reduces the facility’s cooling load compared to air-cooled alternatives but introduces additional liquid-cooling infrastructure requirements.
- Security features: Confidential computing capabilities address data sovereignty and privacy requirements, which are increasingly important for regulated industries and sovereign deployments.
The LPDDR memory choice merits analysis. While LPDDR offers lower cost and power consumption than HBM alternatives common in GPUs, it provides substantially lower bandwidth.
Qualcomm appears to be betting that inference workloads exhibit different memory access patterns than training, making capacity more critical than peak bandwidth.
This assumption holds for autoregressive generation in LLMs, where memory-bound prefill and decode stages dominate but may limit performance in bandwidth-intensive multimodal or vision workloads.
AI250
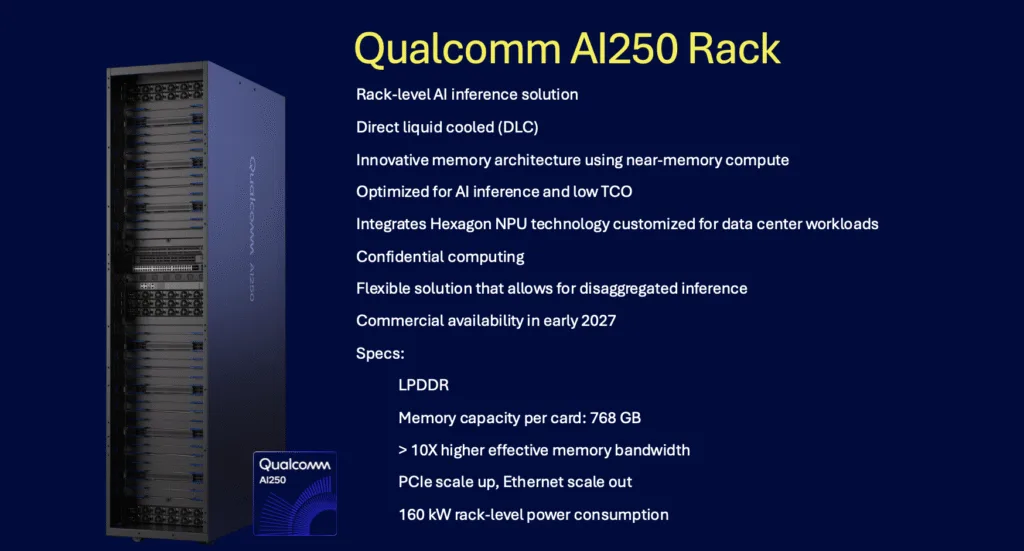
The AI250 is a more aggressive architectural departure, incorporating what Qualcomm describes as “similar to” near-memory computing. The vendor claims this delivers more than 10x improvement in effective memory bandwidth and substantial power reduction compared to conventional architectures.
Specific technical details include:
- Near-memory computing architecture: While Qualcomm has not fully disclosed implementation details, near-memory or processing-in-memory approaches typically place compute elements closer to memory arrays, reducing data movement overhead. This addresses the memory wall problem that increasingly limits inference performance.
- Disaggregated inference support: The architecture explicitly targets disaggregated serving models where prompt processing (prefill) and token generation (decode) run on separate hardware pools.
- Power efficiency claims: Qualcomm asserts “much lower power consumption” without providing specific metrics. Given that the 160 kW rack-level power target matches AI200, the efficiency gains are likely to manifest as higher throughput within the same power envelope rather than an absolute power reduction.
The 10x effective bandwidth claim requires scrutiny. “Effective” bandwidth differs from raw bandwidth, which accounts for actual data transfer efficiency under real workloads.
Near-memory computing can dramatically improve effective bandwidth by eliminating transfers for operations executed in place, but the magnitude of the benefit depends heavily on workload characteristics. Applications with high data reuse see the greatest benefit, while streaming workloads see less benefit.
This is an area that we’ll continue to watch as Qualcomm moves forward with these offerings.
Software Stack and Ecosystem Integration
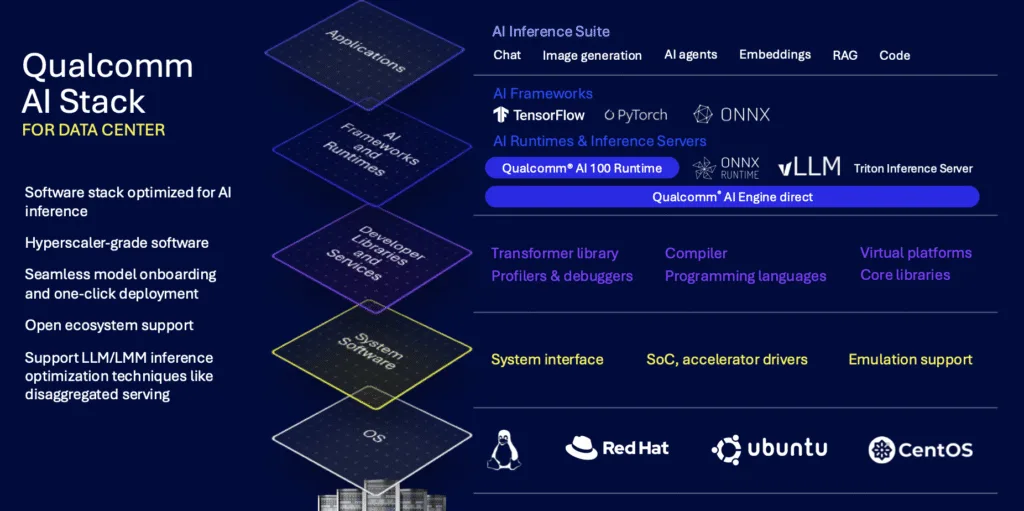
In its announcement, Qualcomm emphasizes software compatibility as critical to adoption, describing a “hyperscaler-grade AI software stack” with several components:
- Framework integration: Support for standard machine learning frameworks and inference engines attempts to minimize porting effort for existing models.
- Model deployment tools: “One-click deployment” of Hugging Face models via Qualcomm’s Efficient Transformers Library and AI Inference Suite targets rapid proof-of-concept development.
- Inference optimization techniques: Native support for disaggregated serving, quantization, and other inference-specific optimizations aligns with the current common wisdom that raw hardware capability requires sophisticated software to deliver competitive performance.
Qualcomm must deliver not just functional compatibility but performance parity across diverse workloads to compete effectively.
The company’s prior work with Cloud AI 100 provides a foundation, but scaling from niche deployments to broad enterprise adoption requires sustained software investment.
Analysis
Qualcomm’s AI200 and AI250 accelerators mark the company’s aggressive move into rack-scale inference, arriving at an inflection point for enterprise AI infrastructure.
The company positions these products against NVIDIA’s inference dominance, differentiating on memory capacity, power efficiency, and total cost of ownership rather than competing on peak performance metrics, where GPUs maintain architectural advantages.
Qualcomm’s approach holds merit for specific use cases. The AI200’s 768 GB memory capacity addresses real constraints in multi-model serving, extended-context LLMs, and memory-intensive retrieval applications that strain GPU memory limits.
The AI250’s near-memory computing architecture, if claims of a 10x improvement in effective bandwidth materialize, could deliver meaningful efficiency gains for inference workloads with favorable data locality characteristics.
The HUMAIN partnership, providing 200 megawatts of deployment capacity, establishes an immediate go-to-market channel. And there may be another design win on the near-term horizon. During Qualcomm’s most recent earnings call, CEO Cristiano Amon indicated that the company was close to a deal to place the AI200 into a “major hyperscaler.” We’ll watch for that deal to close.
However, commercial success faces substantial barriers. NVIDIA’s ecosystem advantage creates a formidable competitive moat that hardware specifications alone cannot overcome. Likewise, Qualcomm is competing against AMD with its MI300-series accelerators and, in the public cloud space, in-house designed inference accelerators (such as AWS’s Inferentia).
Qualcomm must deliver not just functional compatibility but performance parity across diverse workloads while building ecosystem partnerships, establishing reference architectures, and proving operational maturity.
The heterogeneous inference landscape emerging across Groq, Cerebras, AMD, and now Qualcomm reflects market maturation beyond single-architecture dominance. The big question is how many rack-scale inference solutions the market can support – not something we can yet answer with confidence.
Ultimately, Qualcomm’s AI200 and AI250 accelerators expand options for enterprises and hyperscalers during a critical infrastructure buildout phase, where decisions made today establish operational foundations for the next decade of AI deployment.
For AI practitioners, Qualcomm’s entry introduces a meaningful choice into infrastructure decisions. Organizations constrained by GPU memory limits, facing power consumption challenges, or operating in regions with export restrictions gain viable alternatives.
For an industry seeking alternatives to concentrated GPU dependency, Qualcomm’s data center entry represents welcome competition that should drive innovation, improve economics, and accelerate the deployment of inference infrastructure globally, even if the company captures only a subset of the growing inference market rather than displacing incumbent leaders outright.
Competitive Outlook & Advice to IT Buyers
These sections are only available to NAND Research clients and IT Advisory Members. Please reach out to[email protected]to learn more.