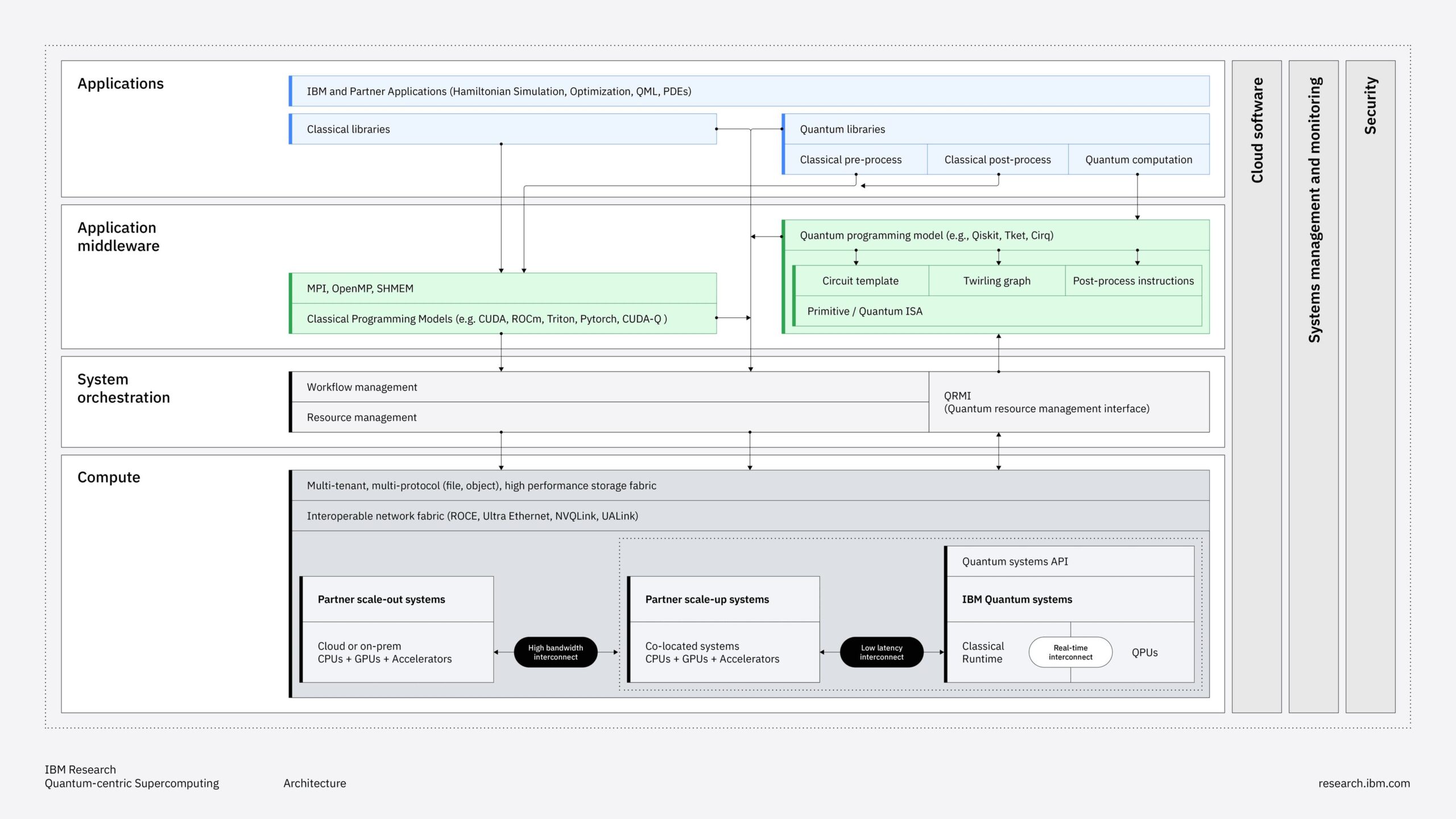
Red Hat released version 3.0 of its AI platform, introducing production-ready features for distributed inference, expanded hardware support, and foundational components for agentic AI systems.
Key additions include the generally available llm-d project for Kubernetes-native distributed inference, support for IBM Spyre accelerators alongside existing NVIDIA and AMD GPU options, and developer preview features for Llama Stack and MCP integration.
The platform addresses critical enterprise requirements for scaling large language models in production environments, particularly around SLA management, GPU resource optimization, and observability.
Red Hat positions the offering as a flexible, hybrid cloud solution that allows organizations to deploy AI workloads across multiple environments while maintaining operational consistency.
Technical Details
Red Hat AI 3.0 builds upon OpenShift AI as its foundation, incorporating several architectural components that work together to provide a comprehensive AI platform.
Distributed Inference Infrastructure
The centerpiece of the platform’s inference capabilities is llm-d, now generally available, which provides Kubernetes-native distributed inference.
This system addresses the unpredictable nature of LLM workloads by disaggregating inference into composable microservices:
- Endpoint Picker (EPP): A semantic router that makes cache-aware and load-aware scheduling decisions
- Separated decode and prefill services: Enables CPU-based prefill when GPU resources are constrained, optimizing resource allocation
- Centralized key-value (KV) cache management: Maximizes cache reuse across workloads to improve performance
- Comprehensive observability: Integration with Prometheus, Grafana, and OpenTelemetry for monitoring the entire inference pipeline
Inference Server Capabilities
Red Hat AI Inference Server 3.2 is the core execution engine for model serving, built on an enterprise-grade version of vLLM. The platform expands hardware support beyond existing options:
- NVIDIA GPUs (existing support maintained)
- AMD GPUs (existing support maintained)
- IBM Spyre accelerators (newly added in version 3.0)
Model Management
The platform introduces comprehensive model lifecycle management through several integrated components:
- Third-party validated model catalog: Features models from OpenAI, Google, and NVIDIA, covering multilingual, coding, summarization, and chat capabilities
- Container-based delivery: Models provided as scanned and traceable containers via the Red Hat AI Hugging Face repository
- Centralized model registry: Enables teams to discover, reuse, and manage models throughout their lifecycle
Performance Metrics and SLO Management
Red Hat AI 3.0 introduces LLM-specific metrics that go beyond traditional application monitoring, addressing the unique requirements of token-based processing.
Customers can now track performance through specialized metrics:
- Time to First Token (TTFT): Measures the delay before initial response streaming begins
- Time per Output Token (TPOT): Tracks the speed of token generation after processing starts
- Cache Hit Rate: Monitors the efficiency of GPU memory usage through context reuse
- Prefill vs. Decode Latency: Distinguishes between prompt processing and token generation phases
- Goodput: Measures requests successfully served within defined SLO budgets
Resource Management
Red Hat AI 3.0 implements several strategies to maximize GPU utilization:
- Accelerator slicing: Supports partitioning of NVIDIA MIG-enabled devices for multi-user scenarios
- Kueue integration: Enables intelligent scheduling across Ray training jobs, training operator-based jobs, and inference services
- Models as a Service (MaaS): Developer preview feature providing control plane with API gateway, RBAC, and cost-tracking metrics
Impact to IT Practitioners
Placeholder for text
Analysis
Red Hat AI 3.0 allows organizations to operationalize large language models with specific requirements around hybrid deployment, hardware flexibility, and operational control. The platform addresses real production challenges around GPU utilization, inference performance monitoring, and distributed system management that have emerged as organizations move beyond AI pilots.
Organizations with existing Red Hat infrastructure investments, requirements for on-premises AI deployment, or strategic concerns about cloud vendor lock-in will find the platform particularly compelling.
For enterprises navigating the transition from AI experimentation to production deployment, Red Hat AI 3.0 offers a pragmatic path forward that balances innovation with operational reality, providing the tools and flexibility needed to scale AI initiatives while maintaining control over costs, performance, and deployment choices. It’s a nice release.
Competitive Outlook & Advice to IT Buyers
These sections are only available to NAND Research clients and IT Advisory Members. Please reach out to [email protected] to learn more.