At the recent NVIDIA GTC conference, WEKA announced the general availability of its Augmented Memory Grid, a software-defined storage extension engineered to mitigate the limitations of GPU memory during large-scale AI inferencing.
This capability targets the rising demand for increased context length support, faster token generation, and lower inference costs as AI models — especially LLMs and large reasoning models (LRMs) — continue to scale in size and complexity.
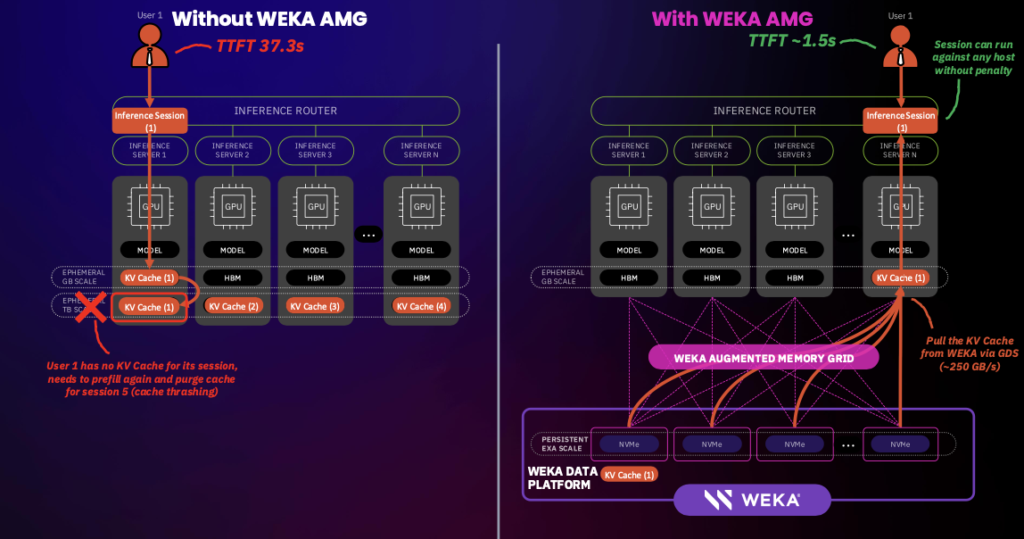
The Augmented Memory Grid is a new approach that integrates with the WEKA Data Platform and leverages NVIDIA Magnum IO GPUDirect Storage (GDS) to bypass CPU bottlenecks and deliver data directly to GPU memory with microsecond latency.
It expands the effective memory capacity for inference systems by using petabyte-scale persistent storage as a cache for inference-related key-value data, such as model prefixes and attention maps. This allows AI infrastructure to offload memory-intensive operations from high-bandwidth memory, improving throughput and latency across inference pipelines.
Background: What is KV Cache?
KV Cache is a memory optimization technique used during the inference phase of transformer-based AI models like LLMs. It stores intermediate data generated in earlier inference steps, specifically the key and value vectors used in the attention mechanisms, so that they can be reused rather than recomputed for each new token processed.
KV caching significantly reduces the computational workload during inference, especially for long prompts or extended context windows, allowing for faster token generation and lower response latency. Without it, the model must recompute attention over the entire context for each token, which leads to inefficient GPU usage and increased inference cost.
Here’s how it works:
- During inference, the model uses queries, keys, and values to compute attention and generate each output token.
- The current query vector is compared to all previous key vectors to determine relevance.
- The model uses the resulting attention weights to retrieve the appropriate value vectors and produce the next token.
Instead of recomputing keys and values at each step, the KV Cache:
- Reuses previously computed keys and values.
- Appends new entries as tokens are generated.
- Minimizes redundant computation, which becomes increasingly costly as input sequences grow longer.
WEKA’s Augmented Memory Grid
Traditional inference systems must overprovision GPUs to compensate for limited onboard memory, leading to high costs and underutilized compute. Models that require longer context windows can exceed the available GPU memory, especially during the decode phase.
WEKA introduces a scalable alternative by offloading KV cache data to persistent memory in its data platform.
Most systems discard the KV cache after prefill, resulting in redundant compute during repeated sessions. WEKA enables persistent storage and rapid retrieval of KV caches, significantly reducing prefill latency.
Here’s how it works:
1. Extending GPU Memory via Persistent KV Cache
- Transformer-based models generate KV pairs during inference, typically stored in GPU HBM (80–100 GB on NVIDIA H100).
- WEKA moves KV cache data to persistent NVMe-based storage within the WEKA Data Platform, freeing GPU memory for core compute tasks.
2. Data Path Optimization with GPUDirect Storage
- WEKA integrates with NVIDIA GDS to enable zero-copy, low-latency data transfer directly between NVMe storage and GPU memory.
- This bypasses system DRAM and CPU, reducing I/O latency and eliminating unnecessary data copies.
3. High Bandwidth, Low Latency Access
- WEKA’s architecture uses a distributed, parallel file system backed by NVMe SSDs and PCIe Gen5 interconnects.
- The system delivers terabytes per second of aggregate bandwidth with microsecond-scale latency, even at scale.
- Data paths are aligned to the NICs nearest each GPU to optimize I/O efficiency.
4. KV Cache Persistence and Reuse
- KV Cache is retained across inference sessions, eliminating re-computation during prompt prefill.
- Persistent caching enables fast retrieval and reuse, improving responsiveness and system throughput.
5. Dynamic Resource Allocation
- Offloading KV Cache to persistent memory allows GPUs to focus solely on token generation and compute-heavy tasks.
- This reduces GPU idle time, improves utilization across the cluster, and supports dynamic switching between training and inference workflows.
Performance Impact
WEKA reports up to 24% reduction in token throughput cost by allowing inference clusters to achieve higher utilization. The system decouples memory from compute, reducing GPU idle time, which typically reaches up to 60% in under-optimized environments.
In a test environment using LLaMA3.1-70B with no quantization or compression, WEKA reduced time to first token (TTFT) for a 105,000-token prompt from 23.97 seconds to 0.58 seconds — a 41x improvement. Of that time, data transfer accounted for less than 0.2 seconds. Similar benefits occurred even at smaller context lengths, including prompts of only 50 tokens.
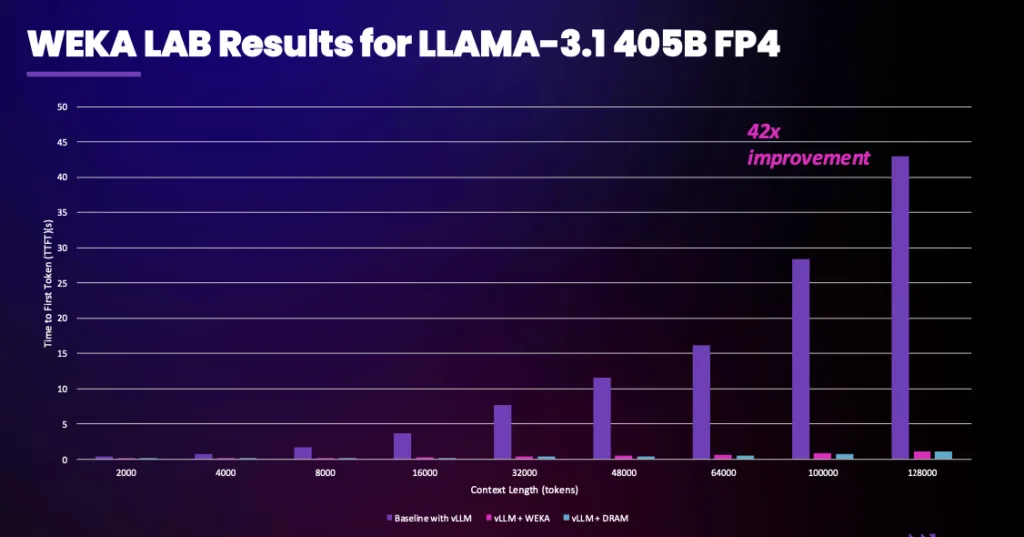
The testbed configuration included:
- NVIDIA DGX H100 system
- 8-node WEKApod with PCIe Gen 5
- NVIDIA Quantum-2 QM9700 InfiniBand (400Gb/s)
This setup demonstrated that WEKA’s architecture can align reads and writes directly to the NIC closest to the GPU, reducing data movement and improving I/O efficiency.
Analysis
KV Cache is a critical component of modern transformer inference pipelines. It improves latency, reduces compute demands, and supports the growing need for long-context, high-performance generative AI applications.
WEKA’s Augmented Memory Grid introduces a scalable approach to resolving one of the key performance bottlenecks in large-scale AI inference: the memory wall. The capability to extend GPU memory with low-latency persistent storage removes the need for costly GPU overprovisioning while improving inference speed and efficiency.
Leveraging NVIDIA GPUDirect Storage to support persistent KV cache is a significant differentiator for WEKA, setting it apart from other AI-targeted storage solutions, which often lack the latency and bandwidth characteristics required for real-time inference. The solution competes with proprietary inference accelerators and custom model-serving pipelines used by hyperscalers and frontier AI labs.
WEKA already provides one of the fastest data platforms for AI at scale. With the Augmented Memory Grid, the company further reinforces its leadership in storage-accelerated AI infrastructure, offering enterprises a practical way to optimize performance and reduce cost across both training and inference pipelines.
It’s a compelling solution.




