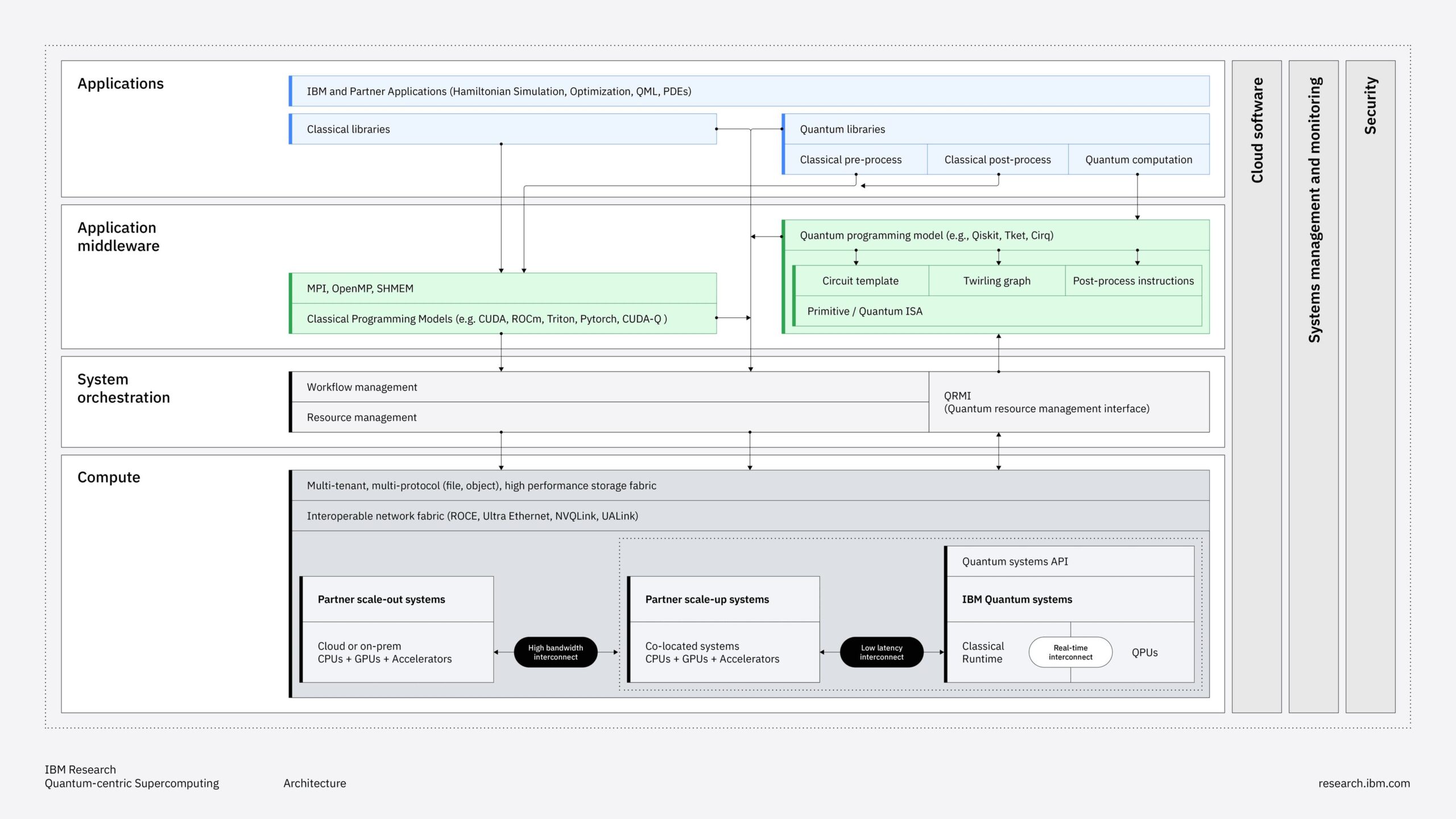
AMD announced a comprehensive portfolio of AI infrastructure solutions at its recent Advancing AI 2025 event, positioning itself as a full-stack competitor to NVIDIA.
The announcements include the immediate availability of MI350 Series GPUs with 4x generational performance improvements, the ROCm 7.0 software platform, and the new AMD Developer Cloud to enable broader ecosystem adoption.
AMD also previewed its 2026 “Helios” rack solution, which integrates MI400 GPUs, EPYC “Venice” CPUs, and Pensando “Vulcano” NICs.
Let’s delve into some of the more interesting aspects of the announcements.
AMD Instinct MI350 Series
AMD’s new Instinct MI350 Series is the latest GPU accelerator family from AMD, built on the CDNA 4 architecture.
The new GPU family targets both AI training and inference workloads, with particular emphasis on LLM inference, where the 288GB memory capacity provides advantages over competing solutions with 192GB limits.
Architecture & Design
Chiplet Construction:
- 8 accelerator complex dies (XCDs) manufactured on TSMC’s 3nm (N3P) process
- 2 I/O dies (IODs) on 6nm (N6) process – reduced from 4 in the previous MI300 series
- 3D hybrid bonding stacks XCDs on top of IODs for high-density interconnection
- 2.5D CoWoS-S packaging connects I/O dies to HBM memory stacks
- Total of 185 billion transistors per GPU complex
Memory & Bandwidth:
- 288GB HBM3E memory capacity (36GB per stack across 8 stacks)
- 8TB/s aggregate memory bandwidth across 128 channels
- Infinity Cache layer between HBM3E and compute units
- 4MB L2 cache per XCD
Two SKU Variants
MI350X:
- 1,000W thermal design point (air-cooled)
- 18.45 PFLOPS peak performance at FP4/FP6 precision
- 4.6 PFLOPS at FP16, 9.2 PFLOPS at FP8
- Standard voltage operation
MI355X:
- 1,400W thermal design point (requires liquid cooling)
- 20.1 PFLOPS peak performance at FP4/FP6 precision
- 5.0 PFLOPS at FP16, 10.1 PFLOPS at FP8
- ~10% higher voltage/clock speeds than MI350X
- ~20% real-world performance improvement over MI350X
System Configurations
8-GPU Platform (Universal Base Board 2.0):
- Shared memory domain across all 8 GPUs
- 2.3TB total HBM3E memory
- MI350X: 147.6 PFLOPS (FP4/FP6), air-cooled
- MI355X: 161 PFLOPS (FP4/FP6), liquid-cooled
Rack Deployment:
- MI350X: 64 GPUs per rack (8 nodes), 18TB memory, 1.2 exaflops
- MI355X: 128 GPUs per rack (16 nodes), 36TB memory, 2.6 exaflops
Key Improvements Over MI300X
- Performance: 4x generation-on-generation AI compute improvement
- Efficiency: Reduced I/O dies enable lower voltage operation and better power efficiency
- Precision: Native FP6/FP4 support for modern AI workloads
- Memory: Higher capacity (288GB vs 256GB) with improved bandwidth utilization
- Inference: 35x inferencing performance improvement claimed
ROCm 7.0
ROCm 7.0 is AMD’s most comprehensive attempt yet to create a viable alternative to NVIDIA’s CUDA ecosystem, with particular emphasis on open standards, enterprise features, and developer accessibility.
The announced (but not yet independently validated) 3.5x performance improvements and enterprise MLOps platform address key adoption barriers, though ecosystem maturity remains a challenge compared to the established CUDA platform.
New Capabilities
Distributed Inference:
- Native integration with open-source frameworks (SGLang, vLLM, llm-d)
- Co-developed interfaces and primitives with ecosystem partners
- Optimized for large-scale model serving across multiple GPUs
- Support for mixture-of-expert (MoE) model architectures
Advanced Data Type Support:
- Native FP4 and FP6 precision support
- Enhanced FP8 implementations
- Algorithmic improvements including FAv3 (Flash Attention v3)
- Structured sparsity optimizations
Performance Improvements
Inference Performance:
- 3.5x inference performance increase compared to ROCm 6.0
- Optimizations for lower precision data types (FP4, FP6, FP8)
- Enhanced GPU utilization and data movement efficiency
- Day-one support for latest models (Llama 4, Gemma 3, DeepSeek)
Training Performance:
- 3x training performance improvement over ROCm 6.0
- Enhanced communication stacks for multi-GPU training
- Improved memory management and kernel optimizations
Open-Source Strategy
Community Collaboration:
- Co-development with leading open-source projects, with contributions to vLLM, SGLang performance optimizations
- Shared interface development for distributed inference
- Open kernel development contests and hackathons
Framework Support:
- PyTorch optimization and integration
- Triton kernel compilation support
- TensorFlow compatibility layers
- JAX experimental support
Analysis
The announcements made at AMD’s Advancing AI 2025 showcased the company’s most comprehensive response to the challenge of competing against NVIDIA’s AI infrastructure dominance. It’s a tough job, as NVIDIA has a strong software moat – especially in training environments – with CUDA while it continues to steadily deliver more systems-level solutions.
NVIDIA maintains significant advantages in software ecosystem maturity, with CUDA’s decade-plus development creating substantial switching costs. AMD’s ROCm 7.0, despite claiming 3.5x performance improvements, still requires organizations to retrain developers and port existing applications. The announced Windows support expansion addresses a key gap but arrives years after CUDA’s comprehensive platform coverage.
This makes ROCm 7.0 perhaps the most important of the announcements, addressing many of AMD’s critical software ecosystem gaps. Marrying ROCm with AMD’s Developer Cloud appropriately targets ecosystem development, though success requires sustained investment and community adoption. Developers must want to come – or be sufficiently motivated.
The new MI350 Series GPUs are solid contenders for enterprise AI from a hardware perspective, delivering competitive technical specifications with superior memory capacity.
Beyond having a compelling and competitive AI software stack, success in the AI GPU market requires thinking at the systems level. AMD’s new “Helios” roadmap positions AMD as the only vendor offering integrated CPU-GPU-DPU rack solutions based on open standards. However, execution risk remains high, given the dependencies on emerging networking standards and unproven large-scale deployments.
AMD’s integrated CPU-GPU-DPU approach leverages its EPYC processor success to offer something NVIDIA cannot: single-vendor optimization across the entire compute stack. The 2026 “Helios” architecture promises 72-GPU unified memory domains that could simplify large-scale AI deployments compared to NVIDIA’s multi-component solutions.
Enterprise adoption will likely focus on specific use cases where AMD’s advantages are clear: high-memory inference workloads, energy-constrained deployments, and multi-vendor strategies. Broader market penetration requires continued development of the software ecosystem and demonstrated large-scale reliability.
The rapid growth of the enterprise AI market provides room for multiple vendors, but AMD must demonstrate production-scale reliability to capture a meaningful share. Customer willingness to diversify beyond NVIDIA depends on AMD delivering on performance claims while building the comprehensive support infrastructure that enterprise deployments require.
AMD has positioned itself as the primary challenger to NVIDIA’s AI dominance, but converting technical capabilities into market share requires flawless execution across hardware, software, and ecosystem development. At the same time, NVIDIA’s dominance requires that the company also execute at the highest levels – both challenges that will define the competitive landscape through 2026.
Remember this: under CEO Lisa Su, AMD has grown its server business from a single-digit market share less than a decade ago to about 40% today. Do not underestimate the company’s ability to deliver when the organization is focused and committed. We’ll be watching.
Competitive Outlook & Advice to IT Buyers
These sections are only available to NAND Research clients and IT Advisory Members. Please reach out to [email protected] to learn more.